
Open Source and Open Seas — or: Why AI will be Open Source
Lessons from Microsoft in the 2000s and Mapmaking in the 1500s

Linux is a cancer that attaches itself in an intellectual property sense to everything it touches. (…) Our goal is to try to educate people on what it means to protect intellectual property and pay for it properly.
Steve Ballmer (ex-CEO of Microsoft), in 2001 interview for the Sun-Times
Microsoft was on the wrong side of history when open source exploded at the beginning of the century (…) The good news is that, if life is long enough, you can learn… that you need to change.
Brad Smith (Vice-Chairman of Microsoft), in a 2021 talk in MIT

In August 2011, Marc Andreesen declared in a famous WSJ op-ed that, “in short, software is eating the world.” (It’s a great prescient piece; if you haven’t ever read it, I strongly suggest you do.) In his own words:
More and more major businesses and industries are being run on software and delivered as online services — from movies to agriculture to national defense. Many of the winners are Silicon Valley-style entrepreneurial technology companies that are invading and overturning established industry structures. Over the next 10 years, I expect many more industries to be disrupted by software, with new world-beating Silicon Valley companies doing the disruption in more cases than not.
He was, naturally, very right. Throughout this time: Here and Waze ate location services; Uber and Lyft ate taxis; AWS and Azure ate self-hosting; Instacart, GrubHub and DoorDash ate last mile delivery; Shopify ate small retail. Those are but a few of a multitude of examples that prove Andreesen’s point.
What was not in his op-ed, however, was what tech stack enabled this. Behind the exponential growth of the reach and importance of software, lied the exponential growth of open-source software, the true foundational layer that powered it all. Uber, for example, openly claims that open-source software was integral to its success since 2009.
Today, over 70% of the world’s 6.5 billion smartphones run on Android, an OS created in 2008. Over 60% of the world’s websites run on Apache and Nginx web servers. Most cloud computing is powered by Kubernetes, and essentially all servers in the world operate on Linux kernels. According to Statista, the majority of tech stacks reported to be chosen by DevOps teams around the world today are fully open source; most report the use of Linux, Docker, Terraform, among other big open source software projects.
As this aptly-titled 2021 HBR article “The Digital Economy Runs on Open Source. Here’s How to Protect It” outlines, the interest in using open source is such that traditional closed-source companies retooled themselves to become contributors to open-source project. AWS, for example, promotes itself as a major leader in open source — and indeed it is, with some 2,000 open-source projects being actively developed by their teams.
The rationale for this interest is quite simple: open source makes debugging much easier; it enables the exchange of ideas that's critical to foster innovation and creativity; and open-source software is, well, free. “Free” changes the economic equation of everything that may lie downstream of the application, hence open source’s ever-increasing presence in the backend/infrastructure layers of our digital lives.
The problem with closed source
Open source is sometimes thought of as software that’s not monetizable since its developers are giving it away to the public. However, that is absolutely not true. Open source surely makes it harder to make money with software, but not as much as most people think.
Compared to open source, closed-source software offers only one additional avenue of revenue: licensing. That’s it. All other monetization avenues are still there: maintenance, optimization, customization, downloadable content (DLC), you name it. Github, Docker, VMWare, Red Hat, Elastic, MuleSoft and Cloudera are just some of the names of companies that operate multibillion-dollar business models that were completely built around open-source software. Essentially, the open-source model trades off licensing revenues in favor of much faster innovation and user adoption.
By licensing revenues, I mean you sell the license to use a software. Licenses can be granted under different regimes — you may receive a perpetual license to use the software, or it could be for a certain period of time, with monthly/annual payments or whatnot; it may even be that a part of the software is free to use, while some other features are paid (a ‘freemium’ business model). In any such case, customers of closed-source software have no rights to share it, modify it or incorporate it into something they build.
Copyrighting software code cannot protect it since, by definition, copyrighting equates to publicly disclosing its content to attest your ownership claim, and disclosing software code equates to giving it away. As such, in order to protect the licensing revenue stream, closed-source companies go to great lengths to protect the privacy of their base codes and choose to distribute their software either in binary code or within their own servers in the cloud.
Let's say, for instance, you're OpenAI in 2020. You spent over $10 million training GPT3 on a supercomputer with 10,000 NVIDIA V100 GPUs. You ponder for a while about what to do with it, tinkering with it, testing it — even adding a Jupyter notebook for people to test it within your servers —, adding several million dollars more to the total development cost. By late 2021, you start selling access to it via API to some niche developers, which helps you recoup a small part of your costs.
By late 2022, you’re confident enough in your instruction-finetuned version that you launch ChatGPT, an app that runs in your own infrastructure and that allows people to ask questions to the model. You know you got something really right since that ends up being the most successful app launch of all time in terms of user adoption.
At this point, you’re, say, $25-50 million in the hole, but what you have in your hands is an incredibly attractive product you can actually charge for. You figure you can charge for access to some of its features, potentially recouping your investment; so, by the time you finish training GPT4 — which set you back anywhere between $100 million and $1 billion more —, you decide on selling access to GPT4 in ChatGPT for $20/month for the general audience.
For the sake of the argument, let’s assume that the development cycle for ChatGPT, including GPT3 and GPT4 training, testing and finetuning, totalled $500 million. Let’s imagine that a Very Good Hacker would find his way into OpenAI’s servers and download a full copy of GPT4’s model weights. Does this mean this Very Good Hacker just steal $500 million in property?
Yes, it does mean that — or maybe even more. And herein lies one of the main fragilities of closed source: you may be one leak away from completely losing your edge. This creates an incentive for companies to overfocus on keeping their current moats in lieu of searching for the best applications for the software they make. (You may argue that OpenAI would never have spent $500 million on open source. But again, Red Hat, VMWare, Docker and all that.)
There are circumstances where a company may wish to reduce innovation and user adoption in their markets. These circumstances are always monopolies. Let’s dig into one of the most overlooked stories of software monopoly in history: cartography in the sixteenth century.
Closed source mapmaking
I asked GPT4 to tell me what are the 5 most famous maps of the sixteenth century, the highpoint of the Age of Discoveries. The unedited output is seen below.

Two German maps, an Italian one, a French one, and a Turkish one. Where are the Iberian names? Remember: Portugal and Spain were the discoverers and the mapmakers of the era. (Don’t be fooled by Christopher Columbus or Amerigo Vespucci being Italians. Columbus lived for a decade in Portugal and was educated there; Vespucci lived in Seville; both worked for Portugal and Spain.)
These map names may not be from Portugal and Spain, but their contents certainly were. Of the top 5 maps proposed by ChatGPT, one is named after an Italian spy that stole it from the Portuguese (Cantino); another is from a Turkish admiral that plundered it from a Spanish ship (Piri Reis); the others come from cartographers that relied on copies of Portuguese/Spanish maps and of the letters written by the actual discoverers, which they obtained by collaboration with other mapmakers. So, while the information contained in them was likely obtained from Portuguese or Spanish effort, the famous maps that we know of today weren't created by the actual explorers —whose actual maps were so secret that they failed to reach us.
This makes sense; after all, the Portuguese and the Spanish treated their maps as state secrets. They masterfully created their maps for their own private use, and went through great lengths to protect their privacy, with strict laws forbidding the sharing of geographical knowledge with foreigners. The Age of Discoveries was the first time that software really ate the world, and that software was closed source — that is, until a spy would steal it or a caravel would be captured, leading to the maps slowly becoming public domain. The Portuguese and Spanish explicitly wanted to reduce the pace of innovation and user adoption of their playing field.
In key ways, this had been a shift in thought from the medieval world. In medieval times, the cartographers of note relied on a type of ‘open source’ mindset — the Abbasid Caliphate (750-1258 AD) famously dedicated itself to building libraries and translating anything they could find to Arabic; two such works were Ptolemy’s Almagest and Geography, treatises that are the foundation of modern cartography. This suddenly changed when the Iberian seafarers started doing their thing. The pioneers created and protected their maps; and the laggards played catch-up by subterfuge, piracy, and academic collaboration.
And being closed source paid off, as Portugal’s history illustrates. There has never been in history a more extreme example of a small nation expanding to such a large extent, and durably maintaining its grip. In his 1969 book, “The Portuguese Seaborne Empire”, the late English historian Charles Boxer investigates this incredible story in detail. In its intro, penned by J. H. Plumb, it reads (page xxiv):
Indeed the greatest intellectual contribution which the Portuguese brought to Europe through their seafaring was geographical knowledge and navigational exactitude. Their charts and sailing directions became the finest in the world. The Portuguese were, indeed, the path-finders of Europe’s seaborne empires.
In 1450, Portugal was a backwater sliver of a country, an area the size of South Carolina with poor soil and hardly 1 million people. By 1500, it was a global power – the world’s first maritime empire, coming as a direct consequence of its geographical knowledge. By 1750, it had grown 125 times to span over 4 million square miles (10.4 million square km), or more than twice as large as the Roman Empire in its peak. This was a bloody history of warfare and carnage; in a big way due to, but certainly not limited to, Portugal’s pioneering role in the Atlantic slave trade — a humanitarian disaster that led to over ten million Africans being forcibly brought to the Americas, half of which would end up in Brazil. That said, it’s undeniable that Portugal’s efforts led to untold riches to the sponsors of the endeavors, and its lasting effects are evident by Portuguese being #5 in the ranking of largest languages in the world in terms of number of native speakers worldwide (over 236 million).
All of it happened strictly based on Portugal being secretive on their discoveries and calling dibs on the territories they found. Ultimately, Portugal had the earliest European maritime empire, starting in 1415, and the last one to be dismantled, with Macau returning to China in 1999.
But operating in closed source isn’t helpful if you lose the informational edge. Once, say, an English pirate had access to a Portuguese map, that’s it — the game changed. And the only thing it took for this to happen was for said English pirate to plunder a Portuguese ship, which happened a lot.
As such, geographical knowledge was bound to diffuse from the Iberian discoverers into the hands of Dutch, English and French pirates, and that it did. Already by the 1600s, these European powers outshone Portugal and Spain in economic and military development. Portugal eventually lost most of its discoveries in Asia and Oceania, and several African possessions, barely retaining Brazil against the Dutch; Spain would lose much of North America to England and France. By the 18th century, it were these new powers, and not the Iberians, that were discovering new places in Africa, Oceania and North America.
The Age of Discoveries illustrate how the typical development cycle of software works. It starts with open source investigations by dilettantes, enthusiasts and curious weird people. Then, a handful of entrepreneurs achieve a breakthrough that dramatically increases the profitability of the endeavor, leading to it becoming closed source. Finally, as the innovation diffuses through all the participants of the sector, there’s a switch back to open source, with a corresponding tapering of the activity’s profitability. In software and in mapmaking, priorities change once a valuable piece of information is discovered, and change again once the knowledge of it diffuses — sometimes violently, other times slowly — to other people.
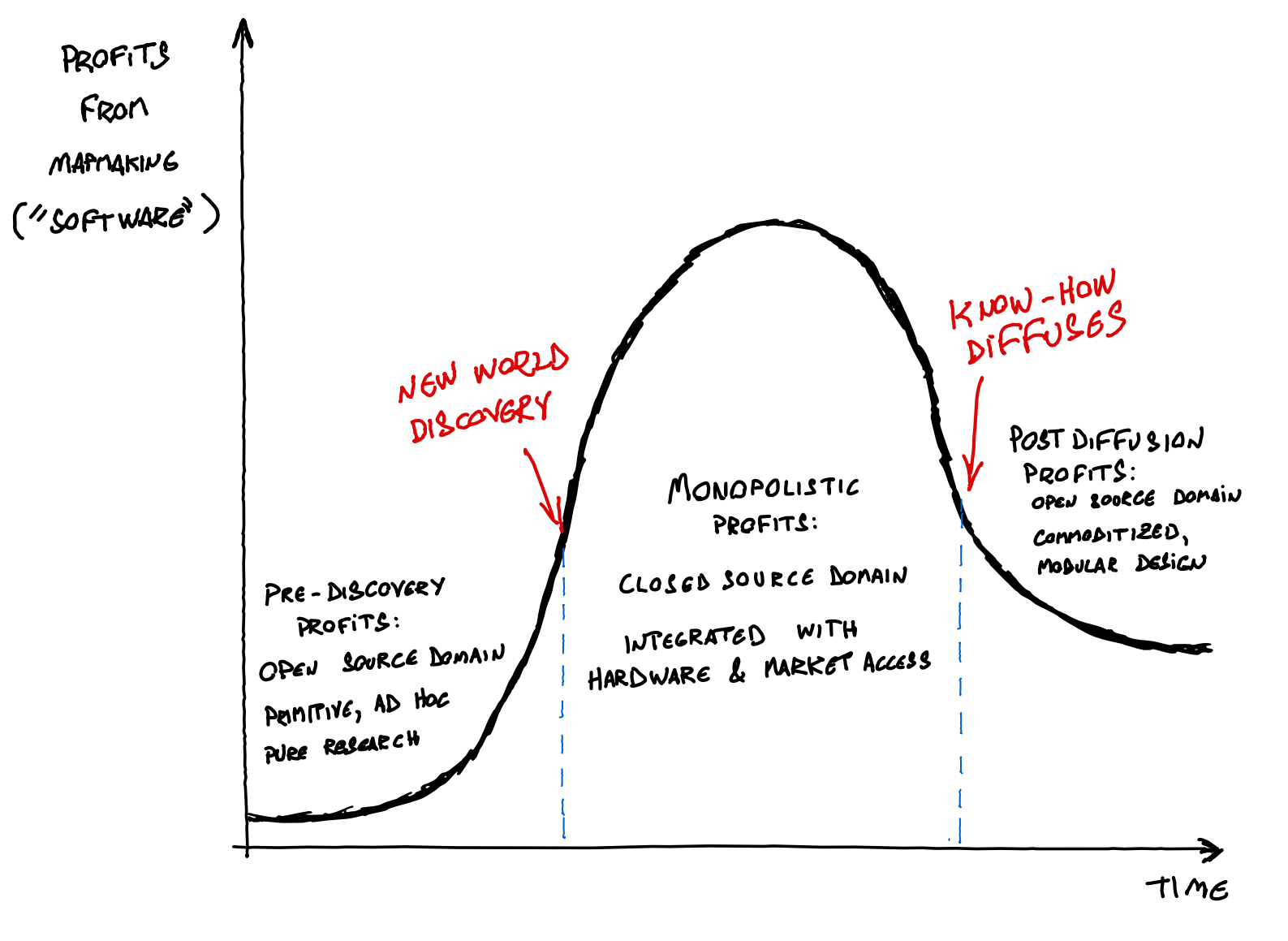
Let’s get back to AI. In the hypothetical case of the Very Good Hacker finessing his way into a full copy of GPT4, we could expect Sam Altman to react exactly as the King of Portugal would have to Cantino’s Planisphere — by denouncing it as an act of piracy, high treason, and maybe even an act of war.
But that does nothing to eliminate the fact that the opening up of the AI industry is bound to happen. An edge that relies on software being proprietary is always temporary, and while you definitely should hang on to your monopoly if you are its owner, you should accept the fleeting nature of it as a fact of life. This process holds true no matter if we’re talking about software that runs on PCs or one that runs on navigators’ brains, whether it was written by computer engineers or by explorers of the world’s oceans.
But you shouldn't believe me on this though. Believe my late professor Clay Christensen from Harvard Business School.
The Law of Conservation of Attractive Profits
Christensen is better known for his Theory of Disruptive Innovation, which postulates that businesses with structurally lower costs end up winning their markets over time regardless of how low the quality of their products initially is. This is so because, over time — and assuming that both the incumbent technology and the newcomer technology continues to evolve —, the newcomer’s less costly technology becomes good enough to attract an expanding cohort of customers, who can adopt that less costly technology to whatever jobs that they need to get done. As time progresses, there is a flight of customers from the incumbent company to the disruptive company, starting from the most cost-sensitive customers and going all the way to the most quality-sensitive ones. Professor Christensen proposed the theory of Disruptive Innovation in 1995, and his ideas were fast absorbed by tech luminaries such as Steve Jobs and Andrew Grove. “Disruptive” became a business buzzword, and the descriptive power of his disruptive innovation theory continues to show. It's an incredibly powerful framework to understand how innovation in business happens.
But this is only one of his several theories. There is another theory of his that may be just as powerful to describe the intricacies of the tech world: the Law of Conservation of Attractive Profits. Described in his excellent book “The Innovator's Solution”, this theory states that when one component of a system's value chain becomes modular and commoditized, the value migrates to another part of the system that remains differentiated and integrated. In other words, when profits in one area decline due to competition or commoditization, they inevitably rise in another area that can still command a premium for its unique, value-adding qualities.
Consider the Discoveries again. It was the time of mercantilism, an economic school of thought that postulated that current account surpluses were the only way for societies to develop — that is, maximizing exports and minimizing imports so as to increase the national product. Mercantilism explained Portugal’s state-sponsored goal of finding a way to India, so as to undercut the Turks and Arabs in the lucrative spice trade.
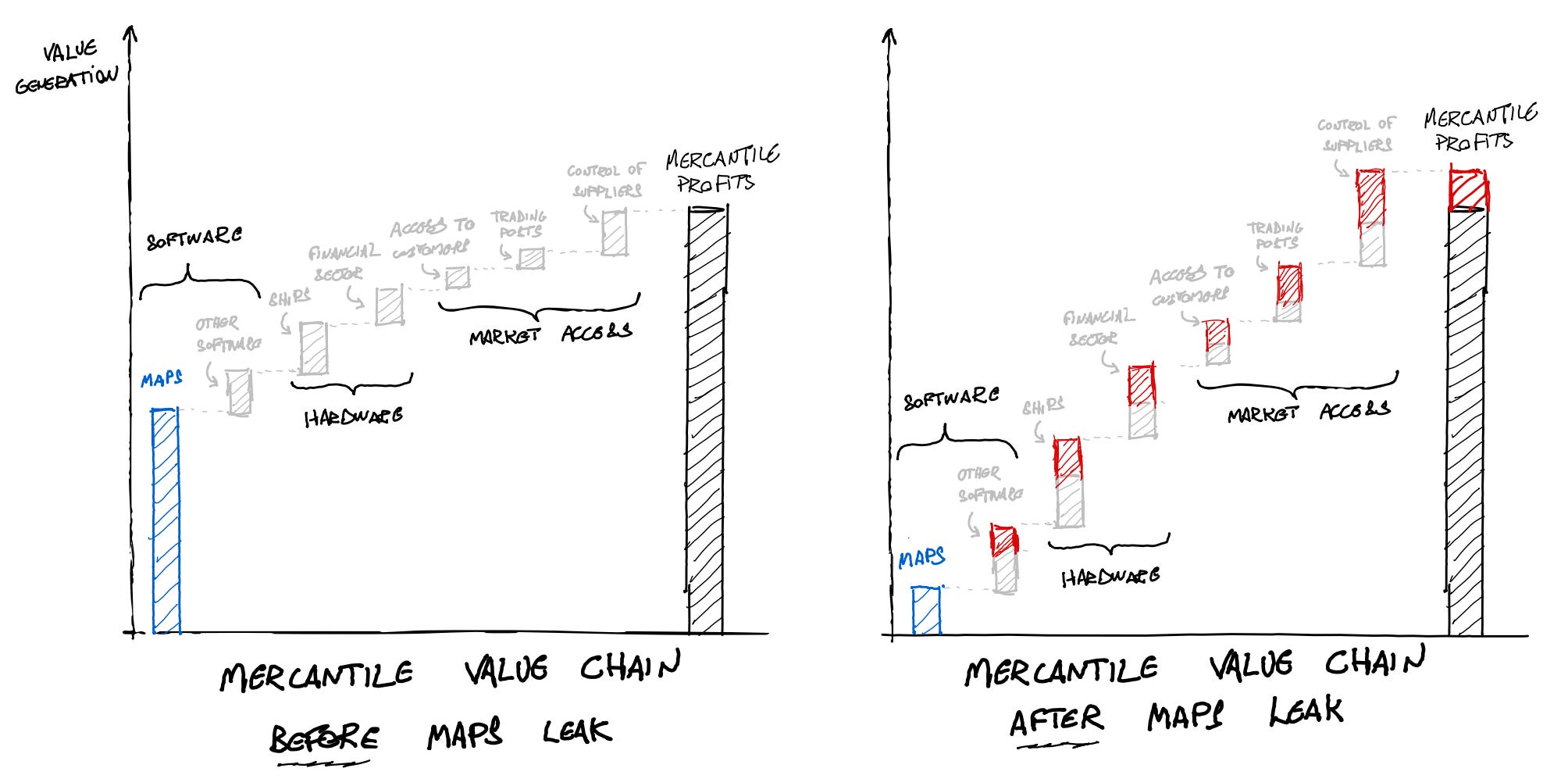
The value chain of an export-based mercantilist state could be understood as being comprised of three interconnected parts:
Software: any and all activity powering the mercantile economy that was inherently knowledge-based. Here, we include: knowledge of sea currents, trade winds, latitude and longitude of new lands, knowledge on where each product could be sourced, mapmaking and navigation techniques, knowledge of foreign cultures and access to reliable translators; etc.
Hardware: here, we include any and all capital-intensive activities necessary to cater to the mercantile industry, including shipbuilding, banking and insurance services, among others.
Market access: here, we include all activities dealing with access and control of areas of production of valuable commodities (spices, valuable metals and other goods); maintenance and control of trading posts (to warehouse goods and resupply ships within their journey); as well as control of the distribution of the sourced goods to the end consumers.
At the start of the Age of Discoveries, the Iberians operated a tight ship (pun intended): they exercised control over all three parts of the mercantile tech stack. On top of holding dearly to their seafaring technology, funding came largely from the crown, which also guaranteed exclusive access to domestic markets for the expedition sponsors. By the start of the sixteenth century, the Hardware and Market Access parts were in good enough shape to allow for a mercantilist economy to arise; the main piece missing was the software, which had to be developed by systematic exploration and documentation. And so the Iberians organized their mercantilist societies to write and exploit the era’s software, which paid off handsomely when the Spanish reached America (1492) and the Portuguese reached India (1498).
For a while, both enjoyed monopolies on their discoveries, since they were the only ones that had access to the maps. As such, a lion’s share of the mercantilist profits came from control over the software part (see illustration below). However, the diffusion of this software component to other players led to that software component losing its value edge, with other parts of the mercantilist endeavor becoming more lucrative as they became more accessible. As dominion over software became less relevant, profits moved towards access to better hardware (bankers in Flanders; Dutch fluytes; English ships-of-the-line) and market access strategies (joint stock companies such as the Dutch and English East Indies Companies; occupation and military control of overseas colonies; plantation building).
The very same frameworks can be used to assess the evolution of the tech industry.
In its initial 30-odd years (from the 1950s to 1980s), hardware profits ruled supreme. Software engineering was deemed a second-class endeavor, and software sales were typically given for free or bundled with the sale of hardware. This held true until computer hardware had become good enough to move the productivity bottleneck to software design. By the late 1970s, innovations such as the VisiCalc, the first electronic spreadsheet, showed that good software could unlock the potential of computers as revolutionary tools.
Accordingly, the subsequent 30 years (early 1980s to late 2000s) saw an exponential growth in the value of the computer software that ran on these machines, which was highly differentiated and harder to replicate. Companies like Microsoft and Oracle were trailblazers with their respective proprietary software. As the discoverers of their respective playing fields, they've made their profits from selling licenses to use their highly differentiated and integrated software. These companies have invested heavily in research and development to continually improve their products, and they've been able to command premium prices because of the unique value they deliver, as this deliciously corny Excel commercial from 1990 (below) clearly display:
But the rise of open-source software disrupted this model. Open-source software, such as Linux or Apache, is free to use and modify, with the source code being available for everyone to see, which makes the software inherently modular and commoditized — as a developer, you could just copy the specific code you need and append it to your project. Open source allowed for massively parallel innovation to occur, speeding up the testing and creation of new ideas and leading to the rapid debugging of software. Just as the leaking of Iberian maps to other European powers led to a surge in competition in transoceanic commerce, open-source software led to the breaking of software monopoly on key parts of the tech stack. This allowed developers with great ideas for use cases (that is, better ‘market access’) to build new products cheaply and reliably, leading to an explosion of adoption of software anywhere — Marc Andreesen’s “software is eating the world” claim.
When commoditization and modularization of a part of the value chain happens, the best response is for companies to move their focus to another part of the value chain, since, according to Professor Christensen's Law of Conservation of Attractive Profits, the value in the industry should then shift to another part of the system that remains differentiated and integrated. We’ve been witnessing this happen with Microsoft in quite a dramatic fashion.
Under the guidance of Satya Nadella, the last 10 years saw Microsoft transforming itself from a proprietary software company that sells licenses to Office and Windows to a hardware-focused company that runs the largest cloud business on the planet by total revenues. Sure, they still sell Office and Windows licenses, but these aren’t the company’s bread and butter anymore, and are largely due to Microsoft’s control of the market access part of the value chain — selling as a cloud-based service, providing access to legacy software, as part of larger deals with corporate customers, ensuring compatibility with legacy hardware, etc. — as opposed to a dogged focus on controlling the software value chain. Evidence of that was Microsoft’s willingness to launch the excellent VS Code as a fully open-source project (seemingly in direct competition with its flagship Visual Studio product).
Whereas less than a decade ago there were voices declaring the death of Microsoft, the company reclaimed the glories of its past and today is again a darling in both Wall Street and Silicon Valley. For the very same reasons, and using the very same evaluation lenses, there’s a lot of talk about Google being in trouble. Google’s monopoly on search could be its very undoing when Mr. Nadella called them out to dance.
In conclusion
In terms of open vs. closed source, AI will not be different: its future lies in open source. It’s just a matter of time and effort, and the effort is certainly under way.
Let’s consider Large Language Models. Ever since Transformers were introduced in 2017, we had BERT (2018) and its family of models, which were open-source models at a time when only the dilettantes paid real attention to next-word prediction as a topic of interest on artificial intelligence. (Indeed, the expression ‘next-word prediction’ still retains some negative connotations in technical AI circles, as if it’s something that is just too simple to be deemed true AI.) As such, little consideration was given to LLMs as a closed source-worthy software field.
Then, comes OpenAI with its crazy belief that they could do something interesting with it. They do GPT (2018), GPT2 (2019), GPT3 (2020). They then reach the “route to India" situation by launching ChatGPT (2022). At this point, everyone and their mother believes in LLMs and the world overshoots towards trying to own this technology. The expectation then switches to AI as a closed source venture, since OpenAI surely will not be willing to disclose their winning methods, datasets and model weights.
Until, of course, someone messed up — by March 2023, an internet denizen leaked away the model weights of LLaMA, a great-performing new LLM created by Facebook. This watershed moment led to the explosion of interest by the open-source community; accordingly, several key innovations begin to show up, such as a 4-bit quantizations that compressed the model with minimum loss of output quality, code that allowed LLaMA to run even in laptops or mobile devices, and novel ways to fine-tune the models in machines with single GPUs. The fact that Falcon-40B and 7B were just released as completely open source (both were relicensed a few days ago as Apache 2.0), is a testament to the new era we are getting in — where the highest likelihood is that free open-source models will eat away the world the same way software ate the world in the 2010s.

What’s equally exciting is the world of generative art.
In January 2021, OpenAI launched DALL-E, the world’s first generative art AI, as an offshoot to the work underlying GPT3. Its results were not really good, but the mere fact that it existed was shocking to anyone seeing it work: you write what you want drawn, and a server cluster in the cloud amazingly spits out a creative rendition of what you asked for. By early 2022, Google releases 2 AIs you probably never heard about (because, Google): Imagen and Parti; by July 2022, two other contenders join the generative art race: Midjourney, and OpenAI’s DALL-E 2. All of which running in the cloud, behind a paywall and a waitlist, controlled by their respective owners/creators.
Then, by August 2022, Stability AI launches Stable Diffusion, which is not only fully open source, but it’s compact enough to be usable on consumer PCs with GPUs from 2016. This meant that anyone with access to some 200 bucks could buy a used computer with a PCIe 3.0x16 slot and an NVIDIA GTX 1060, and generate AI art to their heart’s desire, without any limitations whatsoever.
As a society, we went from not even realizing that computers could create art, to being amazed that it could but having scarce/monitored access to it, to socializing the means of production within the span of 18 months. Karl Marx would be proud.
Whether it takes a few years or a few months, the future of AI will be open source. We in FollowFox intend to play a part in this process and are incredibly excited to be working with you all in it.
Onward!
awesome article,good job man!
I would say you should probably include the NovelAI image model leak in regards to Generative Art Models. If you don't know someone used a zero-day hack to steal the source code from NovelAI along with all the models they had made before they even launched it. Almost every anime/cartoon model derives from those leaks