
Overtrained Text Encoder vs Overtrained UNET [Stable Diffusion Experiment]
Let's look at intentionally overtrained parts of SD model to improve our intuition and understanding

Hello, FollowFox community!
The main goal of today’s post is to improve our understanding of the Stable Diffusion fine-tuning process and enhance our ability to recognize what might have gone wrong during the training.
To achieve that, we intentionally “burned” different parts of Stable Diffusion (UNET and Text Encoder) and then generated many test images to assess how these overtrained models look. This is a long post but has a bunch of interesting findings in it. So get ready, enjoy, and don’t forget to share your feedback and thoughts.
Let’s burn some models!

Overview
If we oversimplify, Stable Diffusion is not a single model but a combination of several AI models. The three main parts are Text Encoder (the model that turns your input text into ‘numbers’), UNET (the main part of the model responsible for creating ‘images in latent space’), and VAE (the part that turns numbers from latent space into images).

Each of these parts has its architecture and its model weights.
When we fine-tune or train the Stable Diffusion models, we typically modify the two parts - Text Encoder and UNET. This means that we are updating the weights of two different models through the same process, and when we get the final, fine-tuned model, we are looking at the results of those two updates. A lot can go wrong during fine-tuning, and detecting the probable cause is critical. Over or under-training the model is the most common cause in general, but if we are evaluating two models through the same process, it’s impossible to tell apart if we had issues with both parts or maybe with just one. It’s even possible that we overtrain one part of the model during the same training process and undertrain the other.
In this post, we will intentionally overtrain Text Encoder first to get a deeper understanding. Then, in a separate fine-tune, we will overtrain Unet. And then, try to show how the output changes as the individual parts of the model get increasingly overtrained and how the overtraining of Unet compares to Text Encoder visually.
The Plan
Training Data
The first decision about the process we had to make was what training data to use. We were choosing between a person, art style, and general-purpose fine-tuning. All three have some pros and cons, and in theory, as a community we should try to test all three.
We decided to start with the art style to keep the scope manageable. In one of our previous posts, we already did some experiments with style (link), so we are reusing that dataset. Specifically, we will use that data's “Long, hand-corrected captions” version. The dataset contains 26 images by Merab Abramishvili (1957-2006), heavily stylized paintings unknown to the base SD 1.5 model.
If you want to experiment with the same dataset, we uploaded it to HuggingFace (link).
Training Protocol
Our goal was to destroy the model and have a series of checkpoints to allow us to see the progression. So we split the fine-tuning process into a few stages.
We started with the base Sd 1.5 model.
To establish a baseline, we did the usual style training protocol for 50 epochs at a 1.5e-6 learning rate.
Then we disabled Text Encoder training to overtrain the Unit. We did two runs: the first was resumed from the above-mentioned 50 epoch baseline and 500 epochs at 1.5e-6. And finally, to get an Extra overtrained model, we resumed from that 500 epoch checkpoint and did additional 500 epochs at a 9e-6 learning rate.
To overtrain the Text Encoder, we did a similar protocol. We disabled Unet training. Trained 500 epochs at 1.5e-6 and then 500 epochs at a 9e-6 learning rate.
You can check the exact parameter files for all the runs on this HiggingFace repo (link).
Testing Plan
For each part (Unet and Text Encoder), we chose 8 checkpoints based on which we will do the testing:
0: SD 1.5 base model
1: Style fine-tuned baseline
2-4: three checkpoints from the 1.5e-6 run, 100, 300, and 500 epochs.
5-7: three checkpoints from the 9e-6 run, once again 100, 300, and 500 epochs.
All the above-mentioned checkpoints were uploaded on HuggingFace if you want to download and experiment more. (link)
As the first step, we will look at training logs to see if anything is interesting.
And then, we will generate many images to observe changes visually. For this purpose, we decided to generate three sets of images (a lot of inspiration from u/alexds9 and his post link):
a photo of Jennifer Lawrence (no activation word used here).
black and white circles (no activation word used here)
a man wearing sunglasses + the activation phrase contained in all the captions of the input data.
If you want to see the exact prompts and generation settings, we’ve uploaded the base version of the images on Civitai (link).
Training Logs
One big takeaway confirmed once again is that validation loss is a very unreliable and hard-to-interpret metric with smaller datasets, so be careful when using it. It’s worth looking at, but you shouldn’t overly rely on it - it helps us to inform what might be happening but is not a definite predictor of superior output from the model.
Style fine-tuned baseline logs
This is mainly for just getting a sense of the baseline values:

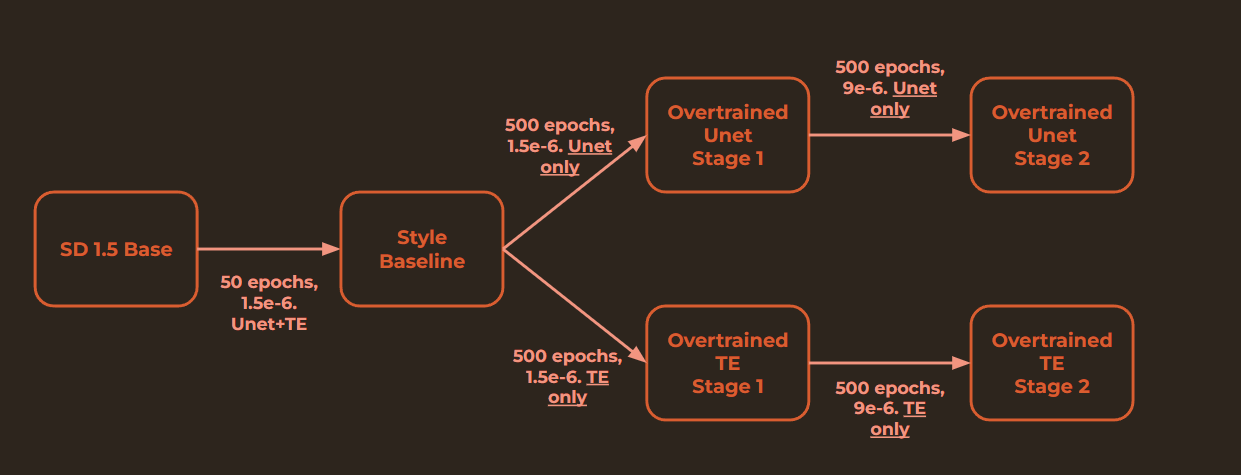
The validation loss shows overtraining, but from previous tests and images generated from this particular run, we know that the model is not overtrained on this particular style - quite the opposite; for a proper generalization, we need to train it further.
However, we can see the usual pattern of negative loss values and the usual shape of the graphs.
Logs of Unet Overtraining
Initial 500 epochs at 1.5e-6.
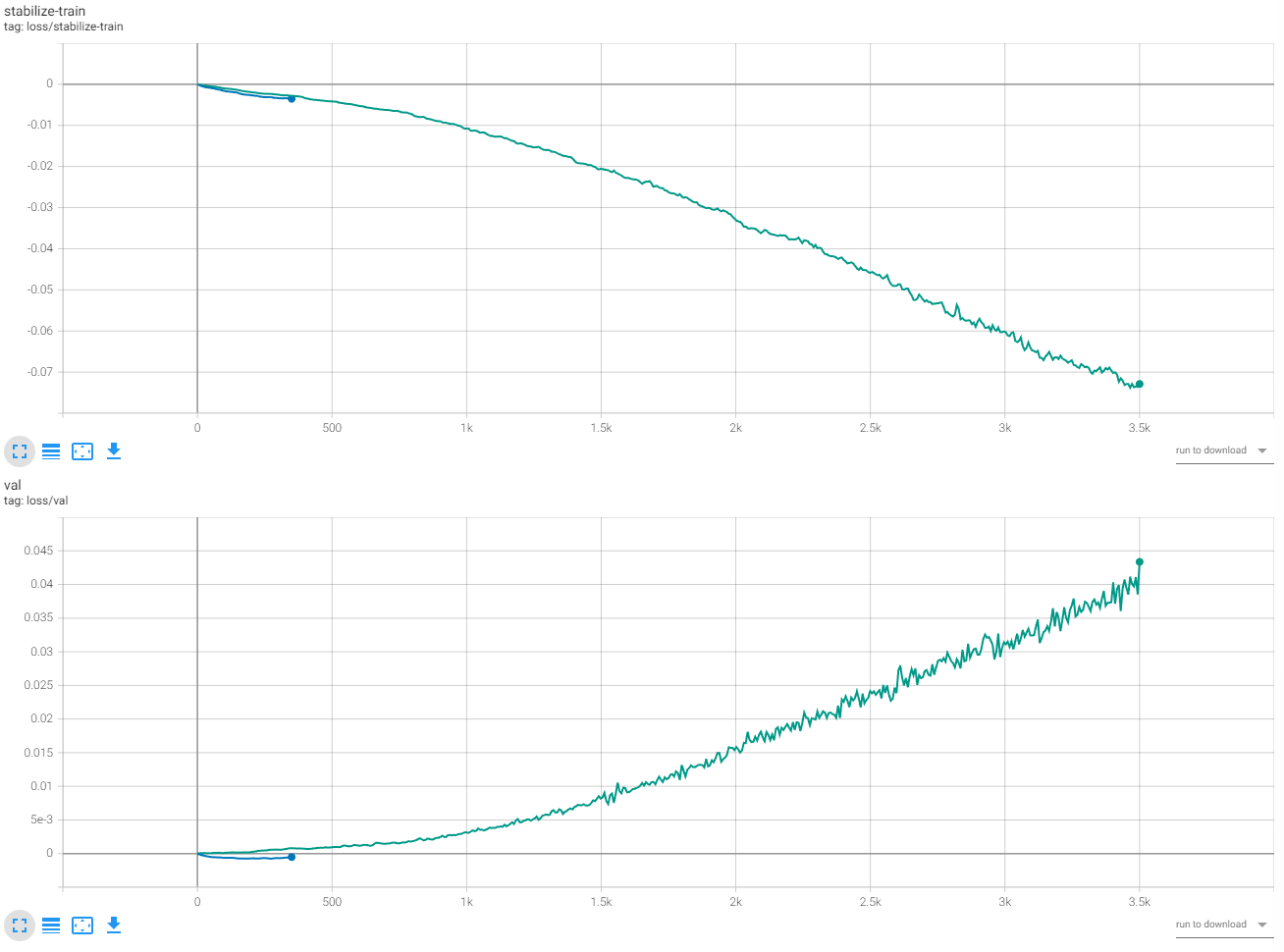
From the start, we observe Validation Loss going up quite a bit. The stabilized loss, as usual, keeps going down.
Adding the Extra run of 500 epochs, 9e-6 reveals a few interesting details:

First of all, the graph is a lot less smooth. The stabilized loss at the start was trending upwards, but later on, more or less followed the typical declining path.
It’s interesting to observe the initial decline in loss on the Validation graph, but then the loss kept increasing. However, despite being less smooth, the absolute values stayed in the same range as the initial 500 epochs instead of going into some crazy range.
Logs of Text Encoder Overtraining
The Text Encoder part of the experiment went unexpectedly in many cases. We believe that this part needs further experimentation and understanding. Compared to Unet, overtraining the text encoder felt hard, and we felt that the optimizer was somehow protecting it. We even did some crazy high learning rate quick tests and didn’t get a super ‘burnt’ model.
Initial 500 epochs at 1.5e-6.
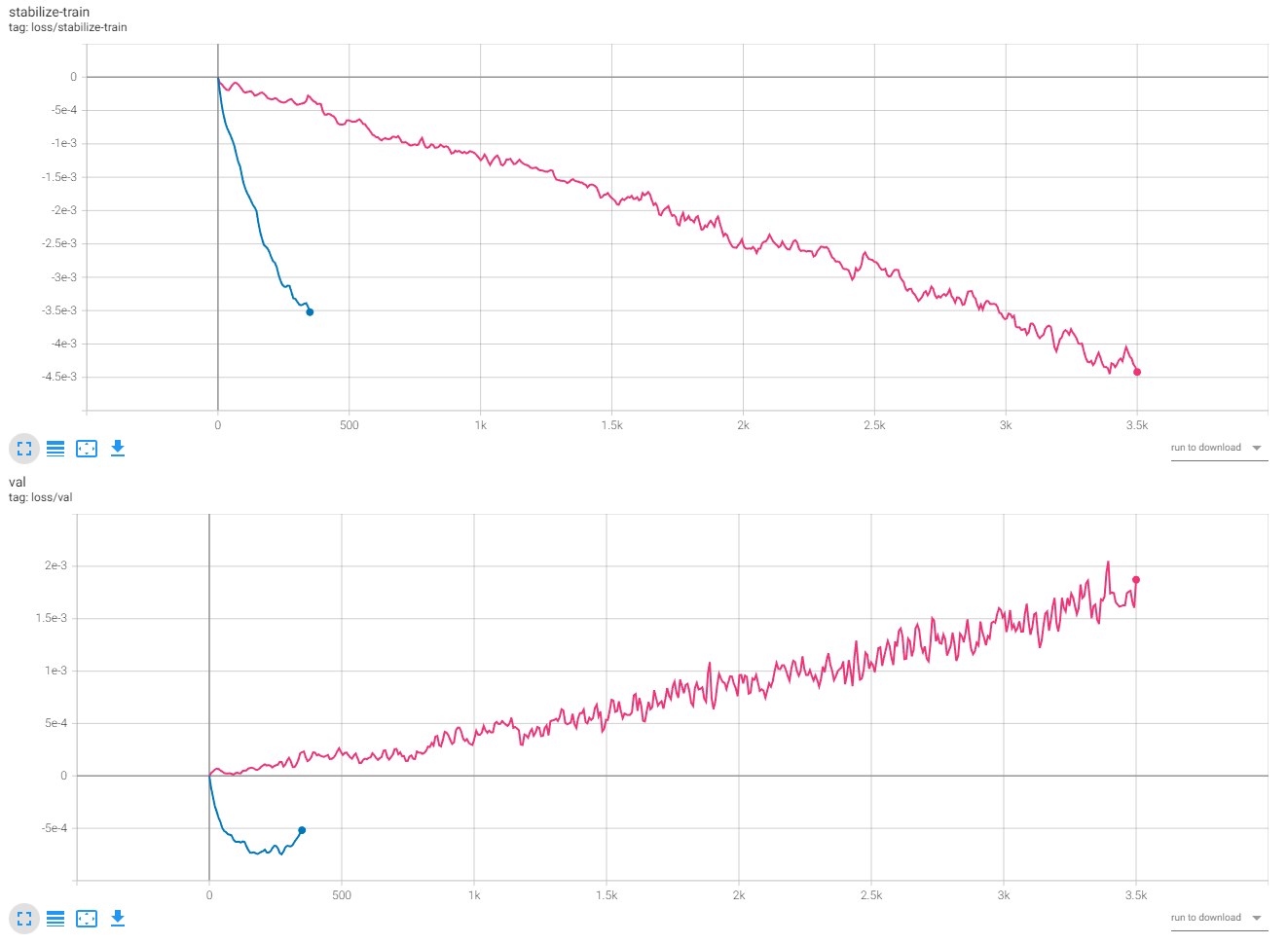
In many ways, the pattern of the first part followed what we saw on Unet, but the absolute values of these losses are tiny compared to the Unet ones. Here is a view displaying both:

Compared to the Unet, TE graph is kinda flat. This gave us the impression that Text Encoder is a bit more stable than the Unet for Sd 1.5.
Extra run of 500 epochs, 9e-6:
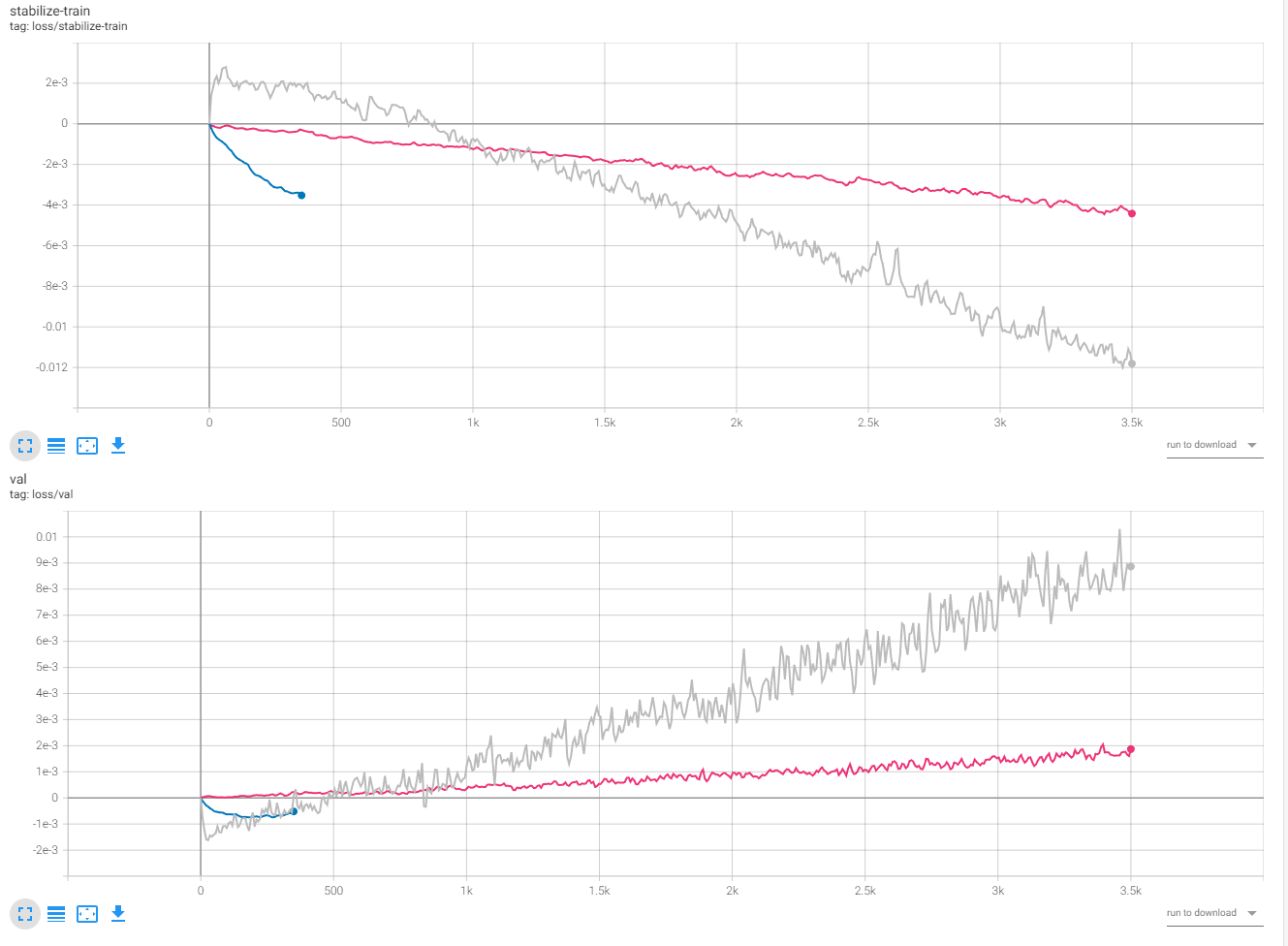
We see a similar reversed pattern at the start of the extra run, followed by the expected trajectories. However, the absolute values are still tiny compared to the Unet runs.
Comparing Output Images
If you want to download all the comparison images and take a closer look, including individual 9 image grids, it’s all on HuggingFace (link).
We will review each test scenario for both cases here. So the order is:
Jennifer Lawrence UNET, followed by Jennifer Lawrence Text encoder
Circles UNET + Cicrles TE
Activation word Unet + activation word TE
Jennifer Lawrence - Overtraining UNET
Let’s start with a quick look at a Gif that shows the progress of the training:

As you can see, there are observable changes throughout and a very strong style bleed towards the end.
Let’s take a closer look at each step, this one image summarizes it well, but we will also upload all images on huggingface and share it:

We see minimal changes from base 1.5 to the style baseline, but the overall quality has slightly improved if one had to argue.
As the UNET overtrains, the biggest observable change for quite some time is a change in the colors of the image. Images are getting increasingly saturated, with higher contrast (we would love input from experienced photo editors on appropriate terminology here).
As we get to the extra training range, weird artifacts appear. Skin and hair start to have a strange and unusual texture.
And at the final step, we see that Jennifer is barely identifiable, the style from source images is bleeding in, and the model is quite broken.
Jennifer Lawrence - Overtraining Text Encoder
Once again, let’s start with a quick GIF:

The changes are still observable but much less when compared to the UNET, and the results never get to that final crazy state.
Now let’s take a step-by-step closer look:

The initial progression of TE overtraining is very continuous, we do not observe much of a color shift as it did in the UNET case, but we see more and more of a strange consistent smile and a strange look/eyes as we go further.
What’s surprising is the last two checkpoints - the weird expressions suddenly disappear. Instead, we see color shifts that are quite significant and a bit similar to what we observed in UNET, but these color changes look more ‘broken’.
Circles - Overtraining UNET
As usual, a quick look at the GIF:

Interestingly, it seems like circles are getting clearer and simpler in the middle part until it gets all crazy towards the end.
Let’s do a closer analysis:

As mentioned above, the circles are getting clearer and clearer as we progress. By the end of the first 500 epochs at 1.5e-6, we are getting almost perfect, simple circles with nothing more in the image. Then slowly, the trained style starts to bleed in, at the start in the background, and by the end, the circles look quite crazy and stylized.
Circles - Overtraining Text Encoder

Changes in the Text Encoder case are much less aggressive, and it’s hard to say if there is a consistent trend. Overall, the shapes have turned clearer, and towards the end, we see the introduction of colors, which seems like the opposite of following our prompt.

The changes seem even more consistent on these three images, but if you look at the 9 full image data, a bit more is going on in a few images. We would love to hear more interpretations of this.
A man wearing Sunglasses + activation phrase - Overtraining Unet
It’s important to note that in the previous two examples, we didn’t use the activation keywords and stayed kinda far from the captions of the training data. It means that most changes observed there is the change in overall model weights.
In this case, we explicitly use the activation keyword in every image of the training data. So we expect to see much more aggressive and observable changes (this is one of the reasons why this test should be repeated for training a person and a general purpose model).

As expected, the changes are way more observable and aggressive. The trained style is getting introduced a lot, and the model is still following the prompt but variability seems to be going down, and towards the end, it’s almost identical and extremely stylized generations.

As mentioned above, we observe a decrease in variability quite quickly. There is a lot of the trained style all across the board. The model still manages to follow the idea of the text prompt input.
A man wearing Sunglasses + activation phrase - Overtraining Text Encoder
Quite a few interesting differences when compared to the UNET results:

Unlike UNET, we don’t observe a total loss of variability. The results are quite stylized, but the style does not accurately represent the trained style. And there are quite a few images where the model is failing to follow the prompt of “a man wearing sunglasses.”

It seems like overtrained Text Encoder might struggle more with following the prompt rather than over-representing the trained style.
What’s next?
There is a lot more to try and test here. For example, the behavior of these models at different inference parameters (CFG is a big one). And then, the test needs to be repeated with different datasets.
However, we think there is enough to analyze and digest from this post. Please share your thoughts, feedback, + suggestions in the next steps of this experiment.
If you like the content, subscribe to our Substack and share the post in various places!