
Stable Diffusion Fine-tuning Experiments with ED2.0 (Part 1)
We experimented with Automatic Mixed Precision, Batch Size, and Image Cropping

Today we are returning to some of the Stable Diffusion fine-tuning experiments; this time, we will use the updated EveryDream 2.0 trainer (link). We will not write the usual step-by-step how-to-install and run guide because the process is relatively well documented. Check out either the video version for a quick start (link) or their doc section on GitHub (link).
We just switched to this tuner, and there is much to test and experiment with. The promising part is the author’s enthusiasm, frequent updates, and the community that has been engaged and growing. That makes us think it is worthwhile to master the tool.
So today is the beginning of that experimentation and learning - we will do a few of many possible experiments and share our results.
Spoiler: You can jump to combined X/Y Plot Results at the end of this post
Setup and Starting Parameters
It’s been a moment since we posted about the fine-tuning model with a person’s face, and we will continue on that. The last time we were using Dreambooth and Damon Albarn’s face (link). We will reuse that exact dataset this time with 20 images. This time we tagged the images using some of the methods explored in our previous post about captioning (link). This is what our dataset looks like.

As a base model, we are using sd_v1-5_vae. You can see all the detailed parameters we used at the start below. These were chosen as more or less starting/default-like values, and the plan is to understand how changing each of these impacts the results.
{
"amp": false,
"batch_size": 4,
"ckpt_every_n_minutes": null,
"clip_grad_norm": null,
"clip_skip": 0,
"cond_dropout": 0.04,
"data_root": "D:\\ED2\\EveryDream2trainer\\input\\damon_test_2",
"disable_textenc_training": false,
"disable_xformers": false,
"flip_p": 0.0,
"gpuid": 0,
"gradient_checkpointing": true,
"grad_accum": 1,
"logdir": "logs",
"log_step": 25,
"lowvram": false,
"lr": 1.5e-06,
"lr_decay_steps": 0,
"lr_scheduler": "constant",
"lr_warmup_steps": null,
"max_epochs": 100,
"notebook": false,
"project_name": "damon_2",
"resolution": 512,
"resume_ckpt": "sd_v1-5_vae",
"sample_prompts": "sample_prompts.txt",
"sample_steps": 300,
"save_ckpt_dir": null,
"save_every_n_epochs": 100,
"save_optimizer": false,
"scale_lr": false,
"seed": 555,
"shuffle_tags": false,
"useadam8bit": true,
"wandb": false,
"write_schedule": false,
"rated_dataset": false,
"rated_dataset_target_dropout_rate": 50,
"save_full_precision": false,
"disable_unet_training": false,
"rated_dataset_target_dropout_percent": 50
}In terms of judging criteria, we will be looking at three main things:
Quality of the results (by far the most important aspect for us)
VRAM usage - relevant in some cases, and as opposed to running it on lower spec machines, we like to think about reduced VRAM usage as an opportunity to push some other settings.
Training time.
Additionally, we will look at ED2’s updated logs and see if anything interesting can be noticed there.
Initial Results - Original Settings
We have to say that the initial results are quite impressive. Especially if you compare it to our results from the Dreambooth experiment (link). Let’s start with the output images:

Realistic photos were not an issue at all and were on par with the Dreambooth experiment.

With avatars, it did pretty well. We think it did better than our previous results.

Superman is where we see the biggest improvement, and now we consistently get good or at least acceptable results.
Logs
Training took 16 minutes and 25 seconds.
Regarding the learning rate, nothing is really interesting as we are using a constant 1.5e-06.

Loss is hard to interpret, as usual. The difference between the two graphs is that one shows loss at every step vs. every 25 steps as we have the "log_step": 25 value in settings.

Performance logs show that the speed has been changing throughout the training, but it is hard to say how significant those changes are (they can be very zoomed-in values). And in terms of VRAM usage, we observe that it hit almost the maximum of 24Gb a few times, went down a bit, and stayed nearby.
Experiment 1 - enabling Automatic Mixed Precision (amp)
In the config file, we changed "amp": to true, and without changing anything else, we launched the tuning. From ED docs, we read:
Enables automatic mixed precision. Greatly improved training speed and will reduce VRAM use. Torch will automatically use FP16 precision for specific model components where FP16 is sufficient precision, and FP32 otherwise. This also enables xformers to work with the SD1.x attention head schema, which is a large speed boost for SD1.x training. I highly suggest you always use this, but it is left as an option if you wish to disable.
And if you want to go a bit deeper, here is a decent explainer we found (link).
Output Quality
Overall, we think output quality went down meaningfully compared to the original run, but the results are still pretty good overall.

Realistic photos are very close to the original run, but these images are slightly less detailed than the previous ones.

Once again, not bad, but we think each image is not as good as the previous ones. It could be rng since we are looking at only four images, but that’s the impression.

In a similar pattern, images 1 and 3 are worse than the previous ones. While the difference in the other two is less noticeable, we think the original settings did better across the board.
Performance
Was the decrease in quality worth it? Maybe.
The training time went down to 9 minutes and 30 seconds. That’s ~42% less time on the same fine-tuning!

No change in the learning rate graph. However, we now see a new graph called the grad scale that we are not yet sure how to interpret.
Loss is all over the place again, and since the two graphs intersected a lot, it’s hard to derive any meaningful takeaways.
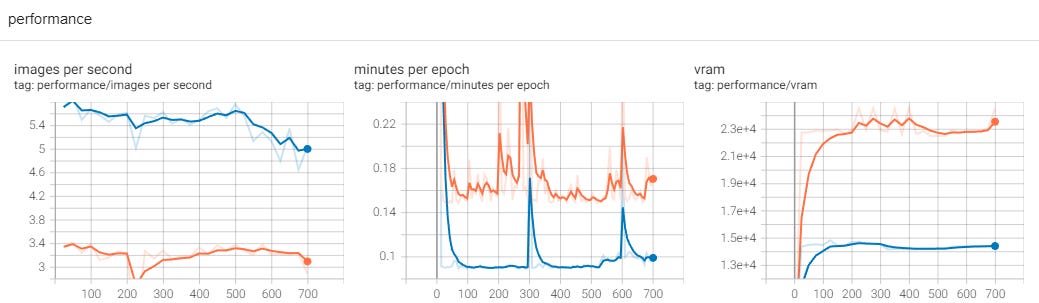
Performance logs show significant gains: we already mentioned ~40% improvement in training time, and we can see that number of images per second has gone up quite a bit, and minutes per epoch have gone down.
It’s interesting to observe the change in VRAM usage; it peaked at around 14.5GB and stayed there throughout the fine-tuning.
Experiment 2 - Batch Size Decreased to Two
In this run, we started to mess with batch size and, in this case, went from four to two by setting: "batch_size": 2. Note that we are not keeping the amp on, ie, each time we will be changing one thing from the original run.
There is a lot more to explore here, so expect more tests, but for now, we just reduced the batch size to see what would happen.
Output Quality
We think the quality has decreased once again compared to the original images. Also, what’s with the always-present neck chain in this one?

Once again, these images are very close to the original quality and almost identical to experiment 1 when we turned on the amp. Slightly fewer details, in our opinion.

Good results but worse than the original. Interestingly, all results lean towards realistic photos compared to the previous two experiments, so we wonder if lower batch numbers could result in the faster fitting of the data. This is just a hypothesis for now.

The first one of the four images seems off, but the remaining three are pretty on par with the original.
Performance
Training took 14 minutes and 36 seconds, so a small, ~11% reduction in training time. Given the batch size change, the trainer changed the total number of steps. Steps increase from the previous 700 to 1200.

No change in the learning rate graph as expected; it’s just longer than the original to account for that increase in steps.
Same here again; no interesting takeaways.

We see a higher performance in terms of speed (images per second and time per epoch). But it was not fully realized as it needed to go for more steps, that’s why we see a reduction in time of 10% only.
VRAM usage also went down to about 17-18GB.
(Failed) Experiment 3 - clip_grad_norm
The run resulted in everything being identical to the original run. Nothing changed.
We set clip_grad_norm": 1. On ED2 docs we read:
Clips the gradient normals to a maximum value. This is an experimental feature, you can read online about gradient clipping. Default is None (no clipping). This is typically used for gradient explosion problems, which are not an issue with EveryDream, but might be a fun thing to experiment with?
This may drastically reduce training speed or have other undesirable effects. My brief toying was mostly unsuccessful. I would not recommend using this unless you know what you're doing or are bored, but you might discover something cool or interesting.
Maybe we entered the wrong value, or it doesn’t do anything with this configuration.
Experiment 4 - Cropping Training Images
In the previous experiments, we observed something odd: epoch_len values (or steps per epoch) were not resulting in the expected values. In theory, each epoch should have steps equal to the number of training images divided by the batch size.
But in the first two runs, we ended up with 7 steps per epoch instead of the expected 5 (20 images / 4 batch size = 5 steps), and in experiment two, we ended up with 12 steps instead of the expected 10.
There is a good explanation for why this is happening - the training data we use have different resolutions that EveryDream is grouping in specific buckets. So there is a chance that some buckets won’t have four images each resulting in more buckets than the perfect fit. and thus in more training steps.
So we wondered what the implication would be of cropping all images to 512x512 and running ED with the same settings.
The results are interesting but hard to conclude - do we see differences due to smaller training data or because all resolutions are now the same bucket?
Output Quality
A slight decrease in quality but the least noticeable of the experiments we have done so far.

Extremely close to the original.

Not as good as the original but possibly better than the other experimental runs. The first image doesn’t look like Damon tho.

Very close to the original, but each image seems very slightly worse.
Performance
This was very interesting to observe. The total steps went down from 700 to 500 (~29% decrease). This resulted in a reduced training time of 10 minutes and 26 seconds (~36% decrease). Unsure why the two percentages are not identical or closer.
We want to learn a bit more about the behavior here when the buckets do not fit perfectly. Almost a 30% increase in steps is significant, and it might be helpful to determine how that impacts the total number of repeats per each of the training images and if it causes some dis-proportional changes between the images that end up in full resolution buckets or not.

This is the first time we are looking at something interesting. We can see two identical graphs that have a consistent gap in-between. Loss values from these experiments have always stayed higher than we observed in the original run.
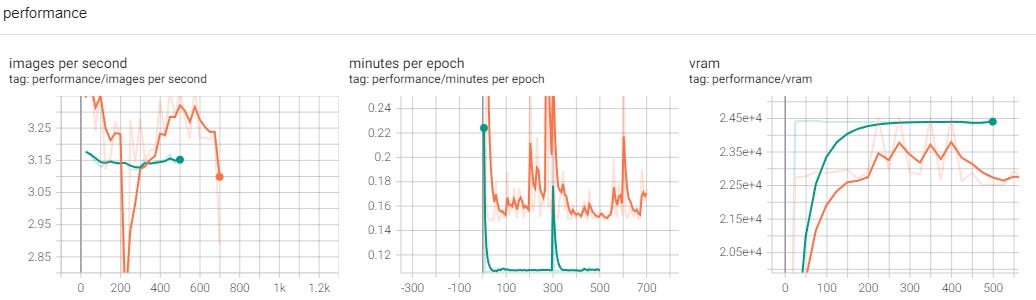
A few more interesting observations here. Images per second are lower than the original, which doesn’t help explain why the time reduction was larger than the reduction in steps. And while that metric is lower, we should expect higher minutes per epoch, but we see the opposite. It has to do something with the number of images per batch.
Finally, VRAM usage was much smoother - it almost immediately reached the maximum of 24GB and never went down until the end.
Combined Results
Heads up: for the vanilla model we user Damon Albarn as an activation word as opposed to a custom keyword (loeb). We might need to look into the fact that the model knows Damon Albarn to some extent even if we are using a totally separate keyword for fine-tuned models.


