

[Part 3] Pair Programming With LLMs on the Example of Image Generation Service (Distillery)
[Part 3] Pair Programming With LLMs on the Example of Image Generation Service (Distillery)
Series to unlock full power of coding with LLMs for non-developers

Hello FollowFox Community!
We are continuing our LLM Pair Programming series on the example of Distillery.dev. Let’s recap what this series is about:
In these posts, we will learn how to master programming with LLMs to understand and create sophisticated services even if you are not a developer. This series will be all about the journey from how we start from a pretty large codebase and with the help of LLMs, learn how it works, what are all the individual parts, and how to improve, document, and contribute to it while being a non-developer.
You can check out the previous posts here:
With this post and the progress - we have a kind of fully open-sourced Distillery: every major part of the system is now documented along with the code. Anyone willing to recreate the system should already be able to do so. There are a few missing parts that we will continue documenting in future posts.
Establishing the Documentation Workflow
In the last part of the previous post, we analyzed and documented the Discord Bot part of the Distillery. Now we have to repeat that for the rest of Distillery’s key parts and given the somewhat representative nature of the task, let’s attempt to establish a process for doing it.
First of all, attaching the whole codebase to the LLM chat interface has been proving to be quite taxing - it is close to the current context length limit of the tool resulting in a relatively slow experience. What’s more - Claude puts hard limitations on how many such long context chats you can have in a given period thus limiting the speed of this exploration quite a bit. There are still specific use-cases (when the holistic overview is needed like Part 1 of our series) when that is the best option.
At the same time, now we have initial parts of the documentation that can be fed back to the LLMs. So instead of giving the full codebase to the LLM, we will attach the latest documentation paired with the code for the part of the Distillery that we are documenting.
The next part that we will be going through is Distillery Worker. So here is the rough process how we will approach this:
Use the repo2pdf tool (link) on the obsidian directory of Distillery’s current documentation to generate one PDF file for the LLM.
Then we export distiller_worker.py as a pdf file (about 800 lines of code).
We attach both files to Claude chat.
Start the process with the following prompt
You are the world's leading developer and expert in writing code. You think about problems holistically and come up with systematic solutions.
The current task is to analyze the code from Distillery and create detailed documentation for every part of it.
We are using markdown output for Obsidian in terms of format.
In the first attached file you can find the current progress on documentation.
Your current task is to proceed with documenting distillery_worker.py - you can see the code attached.
Please create a plan how we will document this and then following your plan let's follow each step and provide neccesary markdown files as expected.Create the documentation step by step assisted by LLM
In the end, generate a new PDF with just created parts of the documentation and ask the LLM to review it and improve it if necessary.
Finally, publish the updated documentation with Obsidian.
Documenting Distillery Worker
We won’t go over all the details that we documented for the Distillery Worker but here is a table of contents with links that should be quite self-explanatory for anyone who is willing to do a deep dive:
We have also included an experimental section on potential future improvements and known limitations to see if LLM can come up with anything interesting and useful in this section that can be used in the future.
We also got this neat graph view of the Worker showing its key aspects.
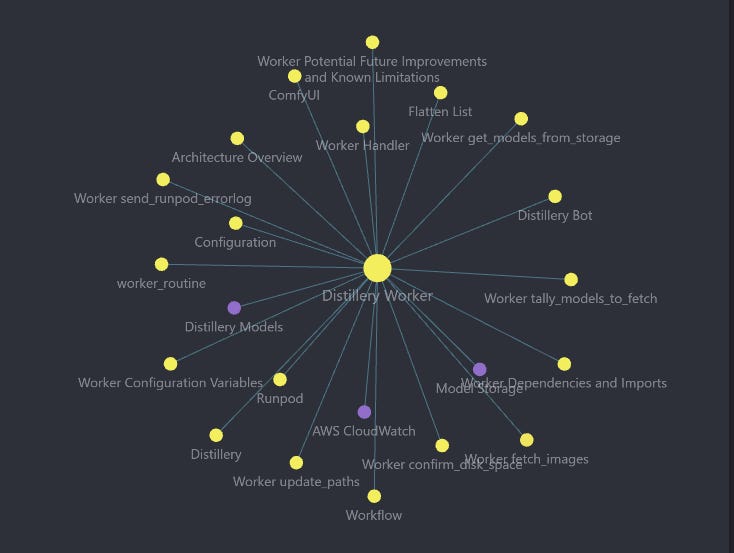
Documenting Distillery Master
Now we can proceed in the same style to document master. We have repeated the steps outlined above and modified the initial prompt slightly.
You are the world's leading developer and expert in writing code. You think about problems holistically and come up with systematic solutions. The current task is to analyze the code from Distillery and create detailed documentation for every part of it. We are using markdown output for Obsidian in terms of format. In the first attached file you can find the current progress on documentation. Your current task is to proceed with documenting distillery_master.py - you can see the code attached. Please create a plan how we will document this and then following your plan let's follow each step and provide neccesary markdown files as expected. Note that in markdown files in obsidian we link things to each other with double brackets - please include this links when things can be connected and if there are new elements yet to be linked, create a placeholder link with [[<md to be created>]] Please closely follow the documentation style of distiller_workerThe following table of contents provides an overview of the key sections and links for anyone interested in a deep dive:
Overview of the Distillery Master's purpose and responsibilities
Configuration variables loaded from
config.jsonand environment variablesIntegration with the RunPod API for sending requests to the Distillery Worker
The main
create_routinefunction for processing requests from the GenerationQueueThe
check_queue_and_createfunction for monitoring the GenerationQueue and triggering request processingThe
mainfunction serving as the entry point for the Distillery Master script
In addition to the detailed documentation, we have also included an experimental section discussing potential future improvements and known limitations. This section aims to leverage the capabilities of the Language Model (LLM) to generate interesting and useful insights that can guide future development and optimization efforts.
Documenting Remaining Key Parts
At this point in the process, given that the workflow was established and it was consistent we decided not to drag on the documentation part and just do all the remaining parts. So we managed to document every remaining critical part of the system with all the details and code:
Distillery Commands link: all the available commands and how they are implemented.
distillery_aws link: responsible for managing interactions with various AWS services and handling database operations.
distillery_outputparser link: responsible for parsing and validating user input, applying parsing rules, and preparing the parsed output for further processing.
distillery_payloadbuilder link: responsible for constructing and preparing payloads for image generation requests. It plays a crucial role in transforming user inputs and configuration settings into a format that can be processed by the image generation backend.
distillery_rawinputparser link: responsible for parsing and processing user input before it's passed to other components for further processing and image generation.
distillery_outputloader link: responsible for processing and uploading files, handling image metadata, and creating command strings.
distillery_maskmaker link: a specialized component responsible for creating and manipulating image masks.
With that, almost every critical component is documented. From the important stuff, we are lacking the documentation of the config files. And then we have a few less critical, helper-type scripts that can be documented from the code.
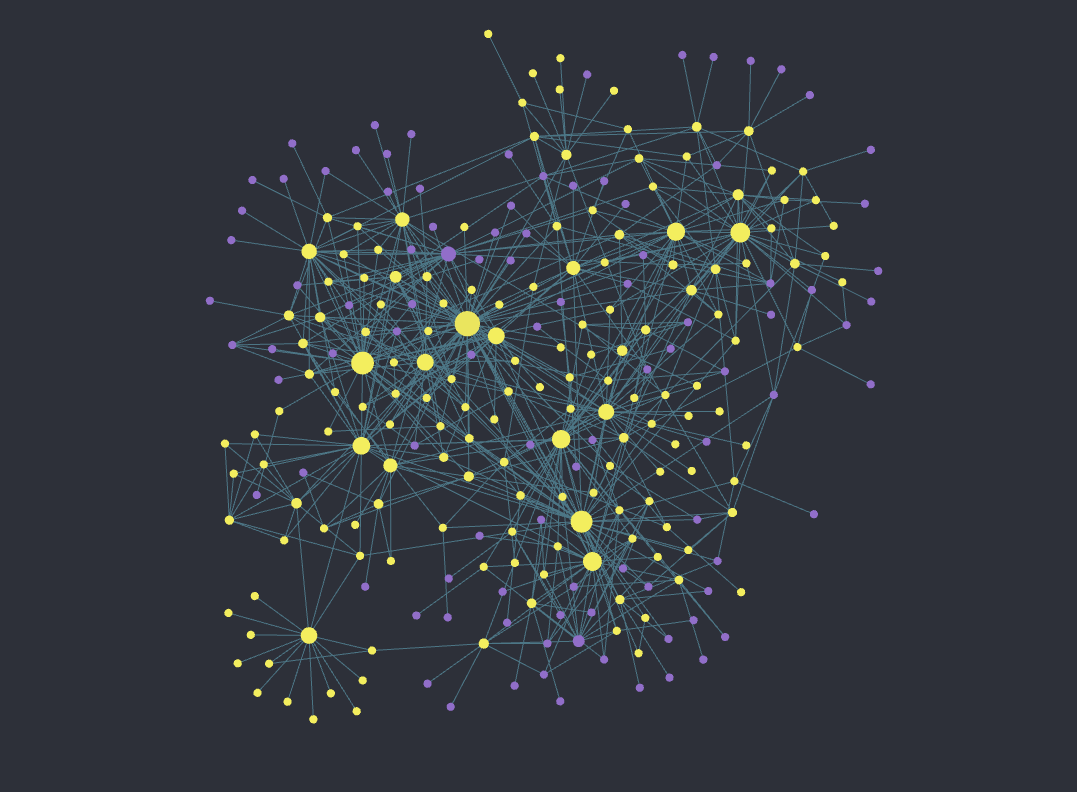
There are also a lot of placeholder links that can benefit from brief definitions for a more holistic experience with the documentation.
Challenges and What’s Next
At this point, we started to encounter the issue that was almost inevitably coming: the documentation in PDF format now is ~300 pages long, 536KB of text, which almost maxes out the largest available context windows.
This means that in order to continue to document and more importantly, efficiently use this documentation with LLMs, we need to figure out how to select out relevant parts of the documentation to feed it back to LLMs within the available context window.
RAGs and vector databases is the first things that come to mind, however, we also have a few creative ideas that we want to attempt and resolve in future posts.
So in the next post, we will attack this challenge with the context window limit and finish up the documentation. Once done, it should open options for more creative usage of everything that we have built.
Stay tuned!
awesome! thanks for share!