
Analyzing Midjourney Discord Usage Data
Releasing a Large Dataset Along with Our Analysis and Interesting Observations

Hello FollowFox Community!
We know that the Stable Diffusion community has mixed feelings about Midjourney. But there is a lot to recognize about Midjourney - they are a household name in the space, one of the largest single communities of AI art, their service has amazing quality with a very low entry barrier for a regular user, and overall they have contributed a lot to this space. And yes, we do wish they were contributing to the open-source world a bit more actively, and also, yes - with the proper workflows, there is a lot more that we can do with SD tools both in terms of quality and more complicated workflows.
Regardless of those feelings, we believe that monitoring what they are doing and learning from their wins and mistakes is very important for advancing Generative AI as a space. And that’s exactly what we will do in this post - analyze a lot of the available data from Midjourney.
And when we talk about analyzing data, we are not talking about the usual surface-level website traffic stats you might have seen online. We will analyze a dataset with more than 16 million rows of entries from Midjourney’s discord. And as always, we share all our code and datasets with you.
Whether you are a Gen AI space enthusiast and want to learn about high-level stats, an SD enthusiast trying to understand and improve your models, or an ML-ops engineer trying to predict and optimize loads on your servers - this post is for you, and you will most likely find something interesting here. So hit the subscribe button, give us credit if you reuse some of these findings, and enjoy the post!
You can also support us by joining and testing our newly launched image generation service on Discord - Distillery.
You will get daily free generations there!
About Dataset, Data Cleaning, and Caveats
Discord Channels
Let’s talk about our dataset. All of it is from Midjourney Discord channels. It is from twenty “#general-00” channels and three “#newbies-00” channels.
As we understand, there are twenty “#general-00” channels in total, so we have data from 100% of those channels, and that’s where the majority of image generation happens when it comes to paid users in open channels on MJ Discord. It is important to mention that many paid users are generating images outside the public channels (by adding the bot to other servers or sending messages directly to the bot). Without further data, it is impossible to guess what portion of all users and image generations are on these #General channels.
When it comes to Newbie channels - new users are randomly added to three of them. And the total number of those channels is 200! So we have ~1.5% representation if we assume all 200 channels are active and users are equally distributed there.
And finally, we know that only paid users can generate images on #General channels. But on #Newbies channels, paid and trial members can generate images. It might be tricky to separate the two cleanly, especially since Midjourney has been controlling the incoming new user waves with some logic that is not known to us.
Timeline and Dates
The dataset we got starts on April 20th and ends on July 9th. However, there is a missing period of nine days between May 10th and 18th. So we will mainly focus on the period starting after May 19th but might check on specific things to that earlier dates.
Initial Data Formats and Combining Datasets
There is a dedicated file per channel, and the whole dataset was split into five different periods. So it was 115 files total (23 channels, 5 periods), and we had to organize and clean them.
Before combining them, we had to understand what’s inside. Each file contains six columns: AuthorID, Author, Date, Content, Attachments, and Reactions.
If you look at Midjourney Discord, all generated images are posted there by Midjourney Bot, and thus, unsurprisingly, AuthorID and Author are generally the same across the whole data. Exceptions are likely mistakenly sent messages by users without a command.
The date column contains timestamps when the bot sent the message in the channel and has a minute-level precision (example: 05/28/2023 12:00 AM). However, we were not informed based on the timezone in the timestamps generated - the server's origin (likely North America) or the location where the dataset was gathered. The difference between the two can impact some of the analysis.
The content column contains the most information - the prompt, the URL to the image if the Image2image workflow was used, additional parameters used, and all kinds of information related to the generated image. We must clean this column to use this dataset properly and carefully. Here is an example of the ‘Content’ column:
**A Anthropomorphic Penguim wearing a stylish and luxurious suit, looking directly at the camera, holding his smartphone with both hands, video recording studio background, bullet time photography, full collors lights --q 2 --s 250 --v 5.1 --style raw --ar 2:3** - Image #2 @redactedThe attachments column contains a link to the generated image. And finally, the Reactions column contains information if and which Emojis were used to react to this particular image.
It is very important to remember that each row of the data represents a message sent by the bot containing an image. This can be the usual text2image initial generation of four images glued into one. Or it can be an upscaled single image, variations generated, img2img, and any other possible workflows. The only way to separate and distinguish these is by parsing and cleaning the ‘Content’ column.
As the first step, we combined all 115 files and added a column called ‘channel’ from the file names to indicate which channel the data is from.
You can find all 115 files uploaded on Huggingface here (link).
And we used the code for initial data combining on Kaggle (link).
Cleaning and Preparing the Dataset
This took some time and effort, and we will not go over every step that we did. However, you can check out the notebook with the detailed code here (link).
There are quite a few things that we need to mention and highlight that will be relevant for further usage of this data.
First, we needed a lot of context on things, and we used two main sources beyond common sense and knowing how Discord works - the announcements channel on Mj Discord and Midjourney’s awesome documentation page (link).
With that in mind, let’s take a look at some important data-cleaning steps we did:
Drop all rows where the 'Content' or 'Attachments' columns is NaN. We also drop all rows where the author is not the Midjourney bot since those are not legit generations. We also did some additional cleaning for weird formatting, etc.
We added a column (“Contains_Link”) that checks whether a prompt contains a link. Those that do are usually some form of img2img workflow.
Some images were not fully generated when the data was scraped, and we added a column called (“in_progress”) that checks if that is the case.
A column called (“variations”) checks if users used some form of variations functionality. ie, generating more variations of a generated image.
Many more columns were added, each dedicated to identifying added features like aspect ratio values, model version, quality values, seed number, etc. These are all the parameters that Midjourney users can specify in their prompts for added control over the image generation process.
We added a column called (“clean_prompts") that contains only the prompt text without all those variables as well as a column called (“prompt length”) with the character count of that clean prompt.
You can find the cleaned, combined file on HuggingFace (link).
We encourage checking this out and doing your analysis - it contains a lot of data that can be used in many useful ways, from dataset curation to user behavior understanding.
With the data ready to analyze, let’s take a look at some of our observations.
You can check the notebook we used for the analytical part but heads up that this is very chaotic and disorganized code (link).
Overall Engagement Analysis
We will use the period starting from May 19th and ending on July 9th as our core analysis dates. The main focus will be data from 20 general channels in this period. We will highlight whenever something different is being analyzed.

Let’s look at the total number of daily images generated daily. We see that, on average, there are ~210k generations, and everything is counted here, from the standard text to image generations, upscale, variations, and many more things that Midjourney users can do. Basically everytime Midjourney Bot sends a message containing an image to the Discord channel is counted as a generation on this graph.
In terms of trends, there are two things noticeable:
Some cyclical type engagement trend, possibly based on Weekdays
And potentially a slight overall negative trend over time.
For a start, let’s cross-check it by looking at the number of daily unique users.

We see that, on average, ~8500 unique users generate images daily. And both the downward and the cyclical trends are even more noticeable here.
Let’s examine those two a bit closer.
Engagement by Weekdays
Let’s look at the average usage and number of unique users by weekdays.


Both graphs confirm that the cycle we noticed is due to the days of the week, and the engagement on Weekends generally goes down. Monday is also part of that trend - probably due to the global user base vs. timestamps in the data from a specific region.
And if you are wondering why unique users have a more defined trend than the total usage, it is due to heavy engagers. They are less likely to not be active on weekends or churn early and are typically responsible for large portions of the overall usage.
Decline Over Time?
While the trend is quite noticeable from the earlier images, let’s examine it closer. Let’s start by looking at the total number of weekly active users. We have data on the full seven weeks in our core period.
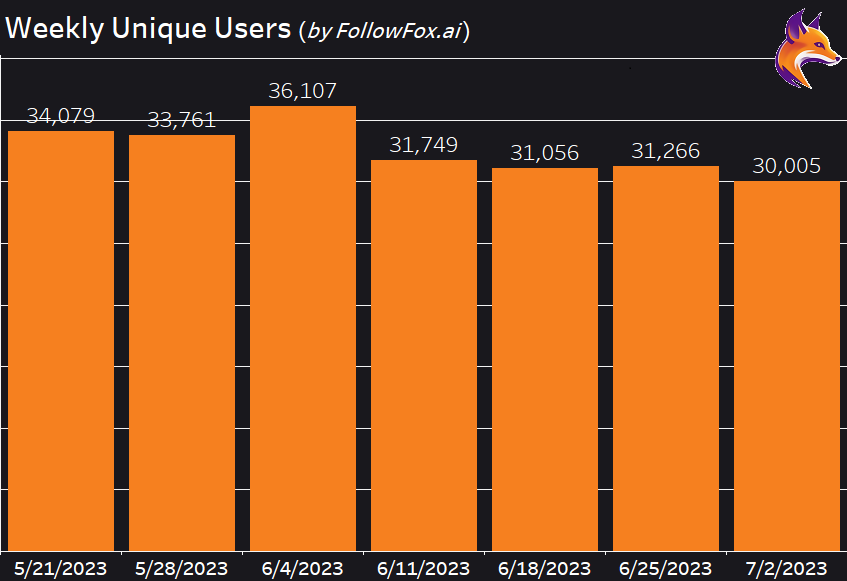
There is a slight negative trend but nothing too concerning (for Midjourney), especially since we don’t know much about the impact of seasonality, possible increase in transition from Discord channels to private chat generation, or even Web generations.
However, if we look at the first and the last week, we see that the weekly uniques have decreased by about 12%, from 34k to 30k over seven weeks.
The conversation on the longevity of this type of business model is a separate conversation that we might write about at some point.
How big is MidJourney’s Subscriber User Base?
This is hard to answer without knowing what portion of users generate images in general channels versus other options MJ provides. Answering this question can help us all to get a better sense.
But if we assume that every user that has generated an image in the #Geneal channel is a paid user, we can get a sense of the ‘at least’ number.
From May 19th till July 9th, we observe 126,523 users.
If we look at the number of monthly active (June 8 - July 8), it’s 78,513. So about 41% of monthly actives (~32,500 per week) are active in a given week. And then, regarding daily actives, we saw ~8,500 users, ~11% of the monthly and 26% of the weekly active accounts.
Remember that all those numbers are “at least” amounts since we do not have deeper insights into user behavior.
New Users and Newbie Channels
We have a very limited understanding of new users, so please be careful when using any of these numbers. We know that paid users can still use newbie channels. At the same time, we do not know when and based on what logic Midjourney grants new users trial access, but when they do, trial users can only use newbie channels.
This means that trial users will only be present in newbie channels but will be mixed with an unknown proportion of paid users. We also know that any given user is assigned to three channels, but we don’t know if the groups of three channels are fixed across users or can be different, meaning the overlap between channels is hard to predict.
With all that context in mind, we see that in the three newbie channels that we have data on, from May 19th till July 9th, there were 7509 unique users. Assuming the distribution across newbie channels to be proportional across 200 channels could mean 500k users. Note that the number is ~4x higher than the number of unique users in general channels.
Please let us know if you have any information and details to make the data here more usable.
User Level Usage
After collective usage, let’s analyze user-level behaviors. Let’s look at the number of generations per user in one month (June 8 - July 8).
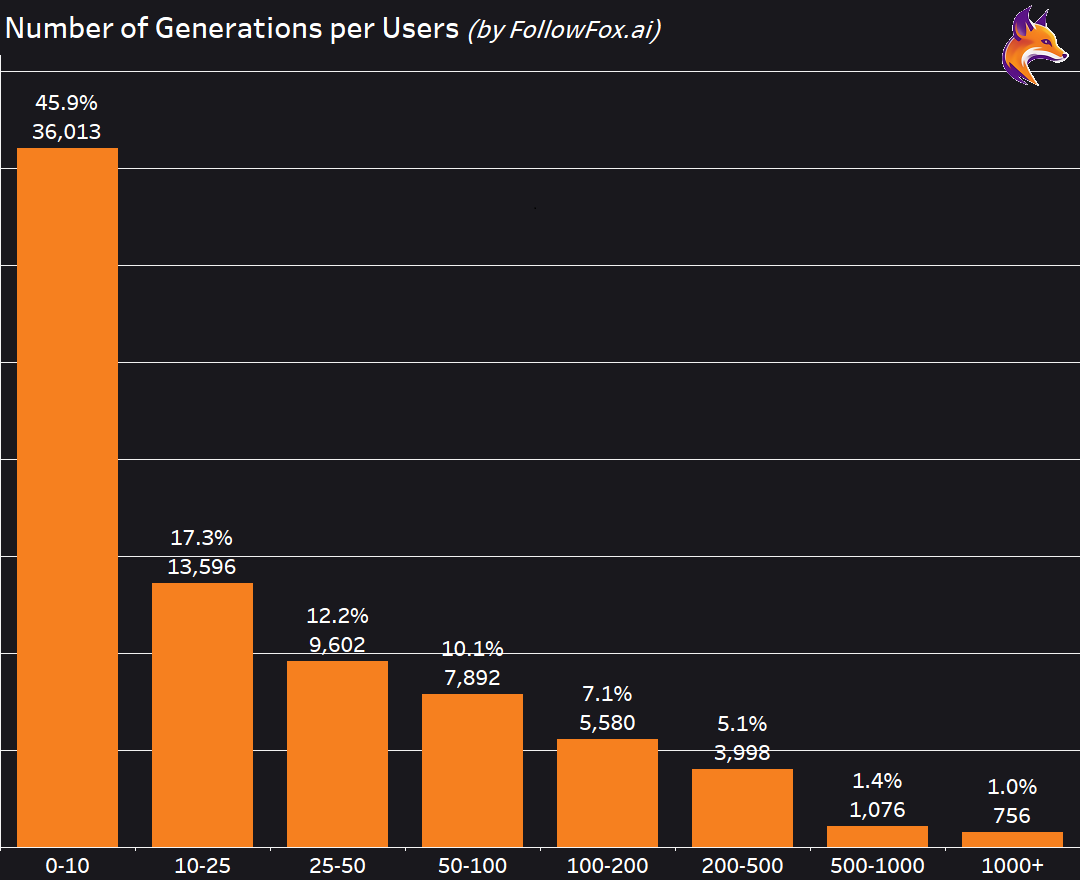
The fact that ~46% of users have generated 10 images or less is a bit surprising, while the rest of the distribution more or less makes sense. Part of that low generations group can be explained again by the users shifting to DMing the bot and not using General channels, but this cannot be the only explanation for that large number.
Low engagement (if that is the case) generally is concerning, no matter the explanation. It doesn't matter if this group represents users who signed up, actively used it for a while, and now are on their way to churning (when they remember to cancel) or it is the just signed-up users who got excited about a few generations and then stopped using the tool.
The engagement pattern is further confirmed if we look at the number of active days per month per user (an active day is defined as at least one generation on that date).
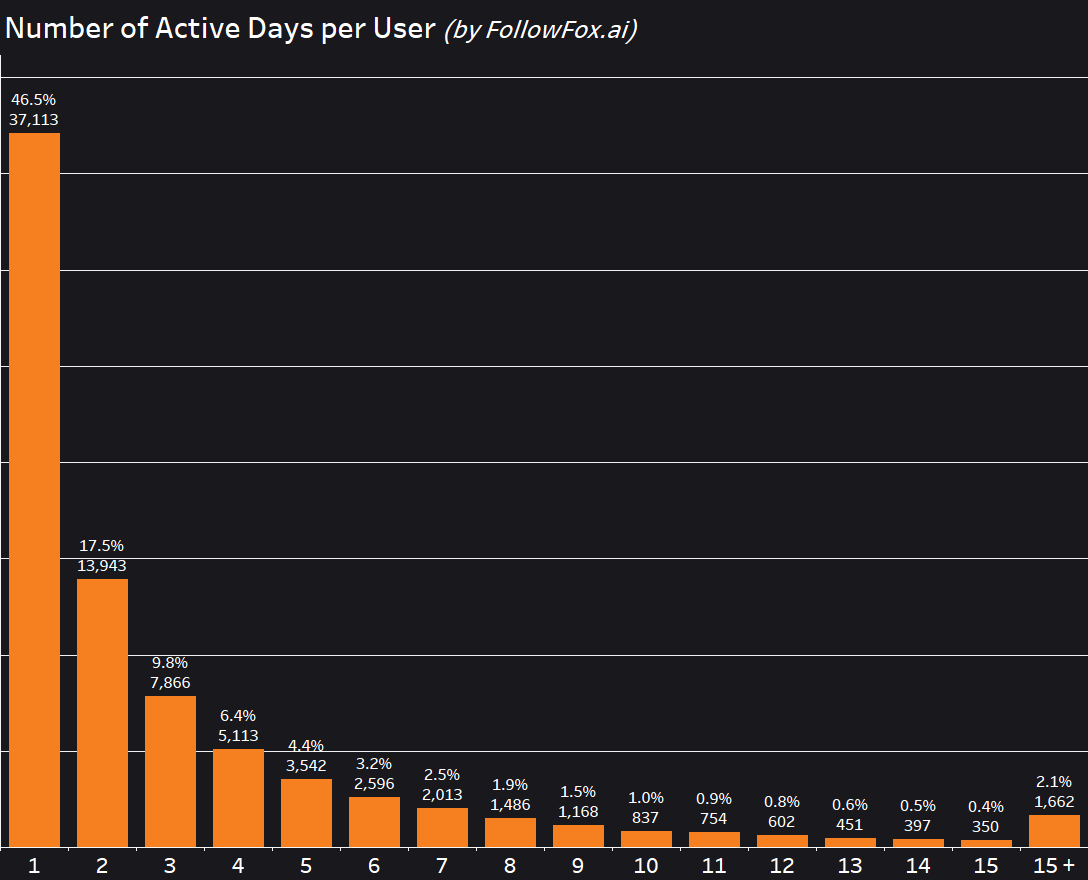
The low engagers group size is very close to the users that have been active just one day.
We would expect this kind of engagement from free trial-type users, but as we understand, only paid members can generate images in General channels.
There is much more to analyze on overall engagement patterns, but for now, we will leave that for you all to explore, and we might come back to it later. Meanwhile, let’s dive into some more specifics of the dataset.
Usage of Parameters and Commands
Let’s look at which functionalities are used by Midjourney users and what are the key patterns. For this section, we are only using data from general channels (newbies excluded), and we also exclude all upscaled image rows since they would duplicate the usage data for those generations.
This leaves us with 9,534,000 generations to analyze.
Niji
Niji is an anime model that Midjourney added in December 2022. This is their collaboration with Spellbrush (link), and Midjourney users can generate images with niji style in MJ discord by adding “--niji” to their prompts. The same model is also available separately on Spellbrush Discord. This is likely some form of fine-tuning of the Midjourney model (but it can also be a standalone model).
We observe that niji model was used 378,558 times which is ~4% of all generations.
Aspect Ratios
Mj users can specify what aspect ratio to use when generating images. If it was not specified or if the specified value was a square (same width and height), then we assume a 1:1 ratio.
We observe that ~66.3% of all generations had a 1:1 aspect ratio, and in the remaining ~33.7% of cases, users have specified some other aspect ratio. And here is the list of the top 10 nonsquare aspect ratios used by the users (the rest is a long list of all kinds of ARs).

Model Version
Users can specify the model version they want to use, and when they do not do this, it defaults to a specific model in that period. This makes the usage pattern very contextual, and looking at overall numbers is useless. Typically it indicates one of three things:
A new version of the model is released, and it is not the default yet, so users are actively specifying the version to test it. In such periods this feature has a spike in usage.
Users prefer other, older model versions compared to the default one.
Users include model numbers in prompts out of habit or because they are copying prompts from those test periods.
This means that depending on what you want to know about this feature and its usage, you will need a custom and closer examination of the data. … but overall, the dataset we analyzed contains ~35.7% of generations with the model version specified.
Since we know that in the last week of our dataset (July 3 to July 9), version 5.2 was a default model, and nothing new was tested, let’s look at the relative usage of version values in that period.
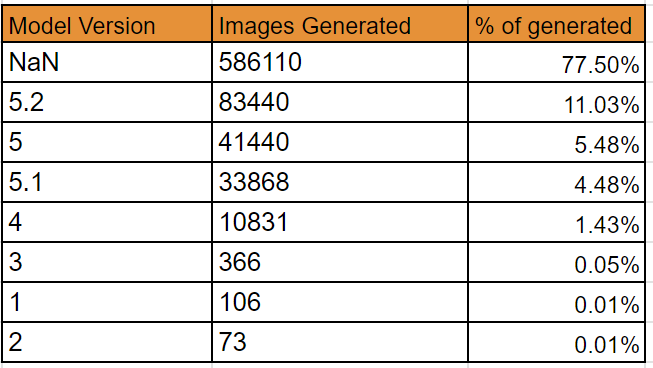
Since 5.2 is already the default, only ~11% of generations had some other model specified - most of them 5 or 5.1. Only ~1.5% of all generations had an older model version specified.
Variations
Variation is the feature that allows Mj users to generate new variations of the prompt by pressing a button. And more recently, in June, they extended this so that users can choose the level of variation they want - strong or subtle.
Overall the feature seems quite popular, and the full data shows that ~23% of all generations are variations. Look at this for the last week (July 3 to July 9) of data.

We observe a slight increase in the overall usage of variations but Strong variations have become the dominant choice when the feature is used. This means that users are looking for larger changes, a different take on the prompt instead of some subtle changes.
Stylize Parameter
MJ users can add to their prompt stylize values from 0 to 1000; the standard value when users do not specify it is 100. This is most likely Midjourney’s take on CFG values as we read it from their documentation:
The Midjourney Bot has been trained to produce images that favor artistic color, composition, and forms. The --stylize or --s parameter influences how strongly this training is applied. Low stylization values produce images that closely match the prompt but are less artistic. High stylization values create images that are very artistic but less connected to the prompt.
Users have used stylized values in their prompts in ~22% of generations. And here are the most popular values that users have used:

So in most cases, users want higher stylization of their images.
Image2image Workflows
When generated images come with a prompt preceded by a link, this typically means that the user has uploaded their image and applied some image-to-image workflow.
Overall, ~15.9% of all generations contain a link.
Style Parameter
This differs from the stylize parameter - users can add one of the available style keywords to be applied to the generation. This reminds us LoRAs of Stable Diffusion. For now, Midjourney offers just a few such styles.
Overall, ~4.6% of images had the style variable. Here is the breakdown of their relative popularity.

Outpainting
This relatively new feature was added in early July, so the adoption and engagement patterns might change. Users can use this function to zoom out of the whole image or expand it to one of the four directions. During the last week of our available data, this feature was used in ~8.1% of generated images. And here is the breakdown:

Interestingly, zooming out is way more popular than expanding images in a given direction, and for some reason, people don’t like expanding images up.
Other Parameters
The rest of the options and parameters we analyzed had usage lower than 1%, so we won’t go any deeper here. However, please let us know if we missed anything important.
Upscaled Images and the Next Steps
As you might have noticed, we have done a basic descriptive look at the data and excluded upscaled images from the analysis. We believe that upscaled images are a great indicator that a user liked a given generation. We can use that information in many ways combined with everything we have discussed.
That is exactly what we will be doing in the next parts of this post when we will use this dataset to generate one or more image datasets for distillation purposes.
Stay tuned, join Distillery, and share your thoughts about the post.