
Dreambooth Face Training Experiment 2- Learning Steps
In part two, we managed to get quite good results, matching some of the best ones so far. Subscribe to don't miss out when we further improvements!

About FollowFox
followfox.ai is an AI exploratory initiative of the boutique marketing agency FollowFox.org.
Until AI takes over, FollowFox.org offers a full range of marketing services at boutique quality by top talent in the region. Support us by:
Checking out our website link
Liking our LinkedIn page link
Checking our sortlist profile link
or by subscribing to this blog
Overview and Setup
A few changes
We decided to move away from using our own faces and bring someone more famous and relatable. We ended up choosing Damon Albarn with some cool future ideas around his persona that we could try. If one day he finds this, we hope he will find it cool, or at least funny.
Experiment Idea and Goals
In the previous experiment, we tried Dreambooth using local GUI, 25 combinations of learning rates, and steps. Check it out, link. Unfortunately, back then, we didn’t get extremely impressive results to match the original target of astria.ai (check our experience with them here link).
This time we got some impressive results. Check our details
Experiment Details and the Optimal Training Protocol so Far
This time we used Automatic1111 WebUI’s Dreambooth on our local machine. Check out the installation details in our post link.
In the Dreambooth extension, the first step is to create a model. The setup we used:
Name: doesn’t matter. Use whatever
Source Checkpoint: We used the official v1-5-pruned.ckpt (link)
Scheduler: ddim
The next step is to select train model details. Our settings:
Training Steps: 10,000. We saved checkpoints at every 1,000 steps. If you want a recommendation, just train the face for 2,000 steps for 20 photos.
Training Epochs: Do not matter as steps override this setting
Save Checkpoint Frequency: 1,0000
Save Preview(s) Frequency: no need, but we had it at 500
Learning Rate: 0.000001
Scale Learning Rate: unchecked
Learning Rate Scheduler: constant
Learning Rate Warmup Steps: 0
Resolution: 512 since we are using resized images at 512x512
Center Crop: unchecked
Apply Horizontal Flip: checked
Pretrained VAE Name or Path: blank
Use Concepts List: unchecked
Dataset Directory and Classification Dataset Directory: whatever directories you have. For training data, we used the following 20 photos.

Classification data: We used 1,500 person_ddim images from JoePenna’s repo. Link
Existing Prompt Contents: Description
Instance prompt: photo of sks person
Class Prompt: photo of a person
Sample Image Prompt/Instance Token/Class Token: all blank
Class Images: 1500
Classification Image Negative Prompt: blank, but doesn't matter since we are using our own regularization image set
Classification CFG Scale: 7.5 but doesn't matter since we are using our own regularization image set
Classification Steps: 40 but doesn't matter since we are using our own regularization image set
Sample Images: none of these setting matter but Sample Image Negative Prompt: blank; Number of Samples to Generate:1; Sample Seed: 0; Sample CFG Scale: 7.5; Sample Steps: 40

Advanced Settings:
Batch Size: 1
Class Batch Size: 1
Use CPU Only (SLOW): unchecked
Use 8bit Adam: checked
Mixed Precision: fp16
Memory Attention: default
Don't Cache Latents / Train Text Encoder / Train EMA: all 3 checked
Shuffle After Epoch: unchecked
Pad Tokens: Checked
Max Token Length (Requires Pad Tokens for > 75): 75
Gradient Checkpointing: Checked
Gradient Accumulation Steps: 1
Max Grad Norms: 1
Adam Beta 1: 0.9
Adam Beta 2: 0.999
Adam Weight Decay: 0.01
Adam Epsilon: 1e-8
Judging Criteria
This section is updated as we try to create a somewhat standardized approach for testing fine-tuned models. We decided that the following three test scenarios make sense and offer tests to judge both the quality and versatility of the model:
A realistic, high-quality photo
Stylized avatar
Fine-tuned subject depicted as Superman
For all 10 models, we scored each of the 8 generated images as bad: 0 points, Good: 1 point, and 0.5 for mixed. So each model can have up to 9 points max per category and up to 27 points in total.
Exact prompts and setting used for judging images:
Realistic
Prompt: photo of sks person, professional close-up portrait, hyper-realistic, highly detailed, 24mm, dim lighting, high resolution, iPhoneX, by Peter Kemp
Negative Prompt: Disfigured, (cartoon), blurry, black and white, female, woman, shadow, painting, shine, reflection, photoshop
Settings: Steps: 90, Sampler: Euler a, CFG scale: 7, Seed: 1991, Size: 512x512
Avatar
Prompt:(sks person), manly face with (scar), warrior, manga, cover art, detailed color portrait, trending on artstation, greg rutkowski, 8 k, smooth render, unreal engine 5 rendered, octane rendered, art style by klimt and nixeu and ian sprigger and wlop and krenz cushart, digital art
Negative Prompt: ((hyper-realistic)), full body, ((far)), letters, dark, shadows, disfigured, (((female))), (((woman))), blurry, bad art, ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), out of frame, extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck)))
Settings: Steps: Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 409286807, Size: 512x512
Superman
Prompt: photo of ((sks person)) as superman, superhero pose, Superman Returns, detailed face, (close up) shot, cinematic, 8k, sharp focus, canon 5d, high-resolution, professional, hyper-realistic, highly detailed, 24mm, sun lighting, high resolution, iPhoneX, by Peter Kemp, city background
Negative Prompt: plastic, toy, blurry, ((far)), letters, dark, ((shadow))), (((disfigured face))), (((female))), (((woman))), blurry, bad art, ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), out of frame, extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck)))
Settings: Steps: 100, Sampler: Euler a, CFG scale: 8, Seed: 3212431291, Face restoration: GFPGAN, Size: 512x512
Summary of Results and Findings
Overview of output ratings
A lot of really good models. One key takeaway - the quality of input images and prompt crafting seem extremely important.
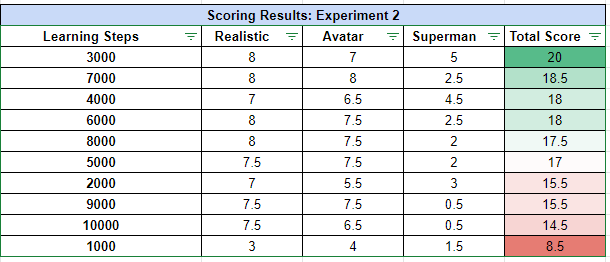
TLDR: 2000 steps can get you pretty good results; we think 3000 did the best, and going to 4,000 or even higher can be better for some specific use cases. Here is the summary of the results:
Bonus: Loss Graph
It’s interesting to see it, and I don’t yet have the expertise to analyze it properly. Still, I will be monitoring these for future experiments and hopefully can draw some conclusions later on.
For now, it’s interesting to observe chaos at early steps - maybe that’s why warmup could be a good idea, and interestingly at ~2k steps, there is a drop - maybe that explains those good results? I’m also tempted to try exactly 2,220 steps (lowest point there) and see if it beats 2k steps one. Please comment if you want me to write a post on how to open these up.

Detailed Results (ranked from best to worst)
1st place: 3,000 steps



2nd place: 7,000 steps



3rd place: 4,000 steps



4th place: 6,000 steps



5th place: 8,000 steps



6th place: 5,000 steps



7th place: 2,000 steps



8th place: 9,000 steps



9th place: 10,000 steps



10th place: 1,000 steps



Future experiments
There is a lot more to try here, so please don’t hesitate to comment if you have a specific one in mind. Moving forward, we will use the optimal setting and change one thing at a time. A few posts coming soon:
Comparing different versions of official SD as a base
Comparing setup schedulers
Experimenting with non-constant learning rates
tbd