Dreambooth Face Training Experiments - 25 Combos of Learning Rates and Steps
We didn't find the perfect formula yet but got close. Plus lot of clues where to look next. Subscribe to don't miss out when we find that perfect combo!

About FollowFox
followfox.ai is an AI exploratory initiative of the boutique marketing agency FollowFox.org.
Until AI takes over, FollowFox.org offers a full range of marketing services at boutique quality by top talent in the region. Support us by:
Checking out our website link
Liking our LinkedIn page link
Checking our sortlist profile link
or by subscribing to this blog
Overview and Setup
Experiment Idea and Goals
We tried astria.ai (post link) a few days ago and got some easy and impressive results. This time we are trying to replicate or improve those results by fine-tuning the Stable Diffusion model on our local machine. There are a bunch of different approaches and settings that can be adjusted, but this time, we focused on combinations of different learning rates and training steps. These are the 25 combinations we tried:

Experiment Details
We used Dreambooth GUI for this experiment (will retry with WebUI or other versions soon). Read how to use the same GUI if you want to replicate the experiment link. More details:
It fine-tuned the “sd-v1-4-full-ema” SD model.
We used the same 20 training images as for astria.ai - this time cropped and resized to 512x512

For instance prompt, we use the word “sks” and for the class prompt, “person”.
The GUI generated 100 regularization images of the person.
For the training arguments, we used the following lines
--mixed_precision=fp16--train_batch_size=1--gradient_accumulation_steps=1--use_8bit_adam--resolution=512--gradient_checkpointing--train_text_encoder
Judging Criteria
Since we wanted to match astria.ai results, we downloaded the checkpoint from astria and generated two sets of comparison images. For our experimental models, we use the exact same prompts, settings, and seeds to generate the images. For rating each of the fine-tuned models, we used a somewhat subjective three-point scale:
Bad = nonsense or not even close to astria
Medium = Some resemblance but not as good as astria
Good = On par or better than astria
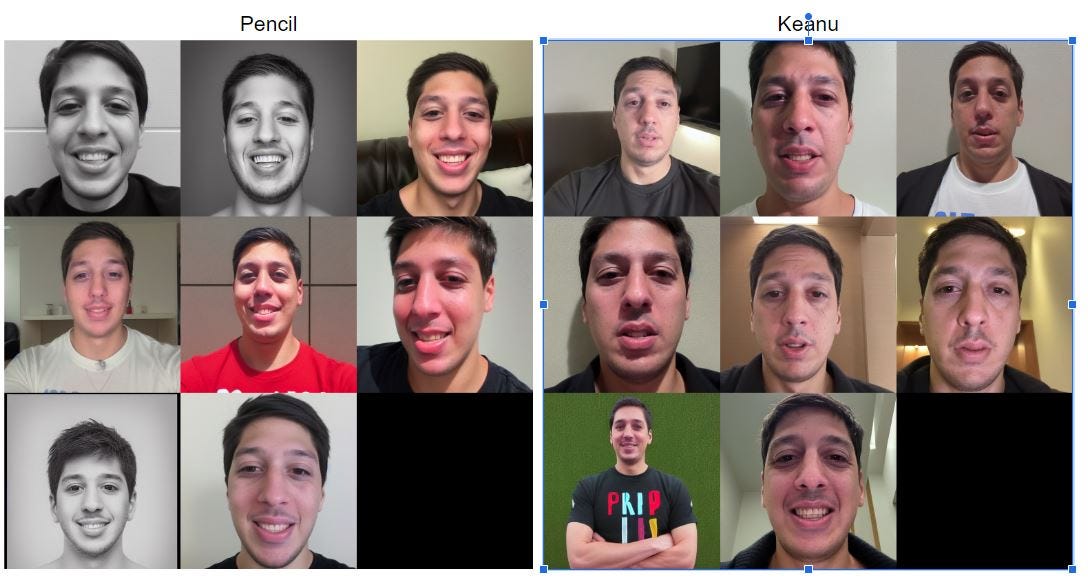
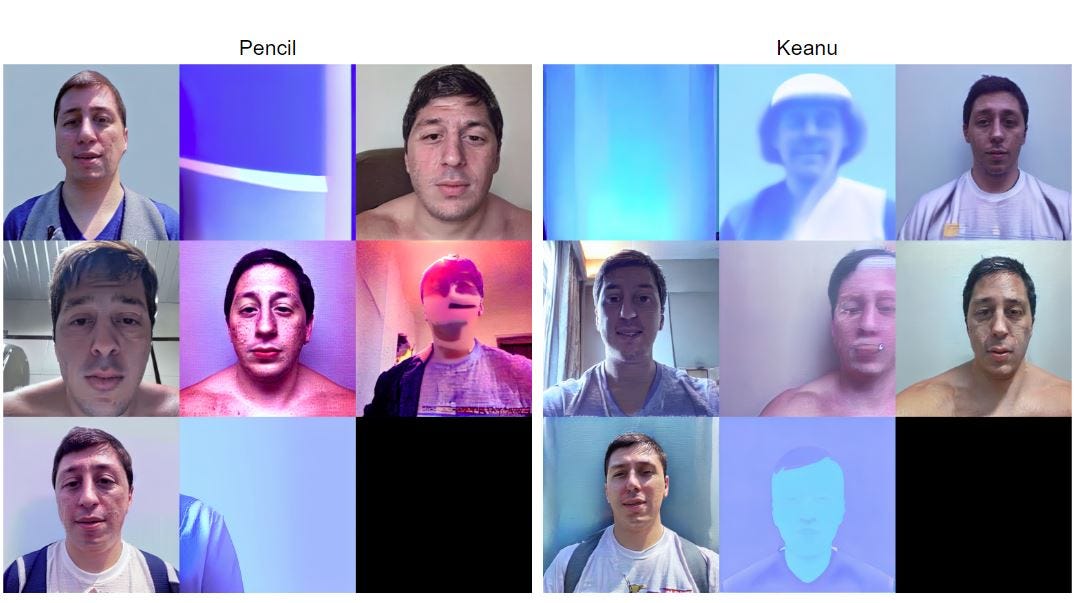
Here are two sets of comparison images based on astria model:
Pencil Sketch:
Prompt: sks person, pencil sketch of a teenage boy with short side part light hair smiling trending on artstation
Settings: Steps: 40, Sampler: Euler a, CFG scale: 7.5, Seed: 1991, Size: 512x512

Keanu:
Prompt: highly detailed portrait of sks person as keanu reeves in gta v, stephen bliss, unreal engine, fantasy art by greg rutkowski, loish, rhads, ferdinand knab, makoto shinkai and lois van baarle, artgerm, pixar, ilya kuvshinov, rossdraws, tom bagshaw, global illumination, radiant light, detailed and intricate environment
Settings: Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 4243591472, Size: 512x512


Summary of Results and Findings
Overview of output ratings
This is subjective, but we don’t think we found a combination that works as well as what astria.ai managed to get. Here is a summary of our ratings, more details, and all the outputs in the detailed section below.
TLDR is that learning rates higher than 2.00E-06 seem irrelevant in this case and that with lower learning rates, more steps seem to be needed until some point.
Overall I’d say model #24, 5000 steps at a learning rate of 1.00E-06, performed the best

Other Findings
A few other interesting things that we noticed that might be useful if properly interpreted:
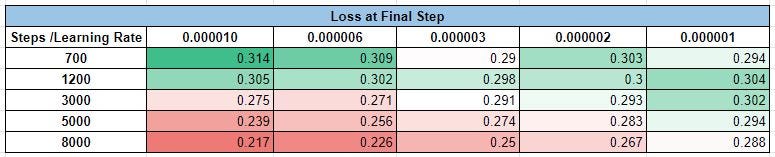
Loss values at the final step:
In general, with more training steps, the final loss value goes down (the exception was model #21).
The absolute value of the final loss doesn’t seem to correlate with the fine-tuning quality.
At each given step quantity, the final loss number seems to go up when we decrease the learning rate. This logic seems to break at a step count below 3000.

Training time doesn’t seem to be impacted by the learning rate and is directly correlated to the number of steps. ie, each step takes the exact same time.

What to try next
Other more flexible Dreambooth training methods, like the Webui addon
Better class regularization image set
Less training images
More variation in 2.00E-06 and lower learning rates
SD 1.5 instead of 1.4
Detailed Results
Model 1: 700 Steps @ 1.00E-05.
Pencil: Nonsense with some resemblance in a few crazy images
Keanu: Nonsense, with a bit of my face

Model 2: 1200 Steps @ 1.00E-05.
Pencil: Some cartoony-looking sketches
Keanu: Weird random faces

Model 3: 3000 Steps @ 1.00E-05.
Pencil: weird faces, no details of anyone
Keanu: More colorful nonsense

Model 4: 5000 Steps @ 1.00E-05.
Pencil: nonsense images barely resembling faces
Keanu: Blue nonsense

Model 5: 8000 Steps @ 1.00E-05.
Pencil: nonsense images barely resembling faces
Keanu: More colorful nonsense

Model 6: 700 Steps @ 6.00E-06
Pencil: At least clear faces, some in pencil but nothing like a trained face
Keanu: Some random cartoony faces with beards

Model 7: 1200 Steps @ 6.00E-06
Pencil: A few pencil sketches with some similarities to trained face but overall, not great
Keanu: Realistic, looking like training faces, but no Keanu
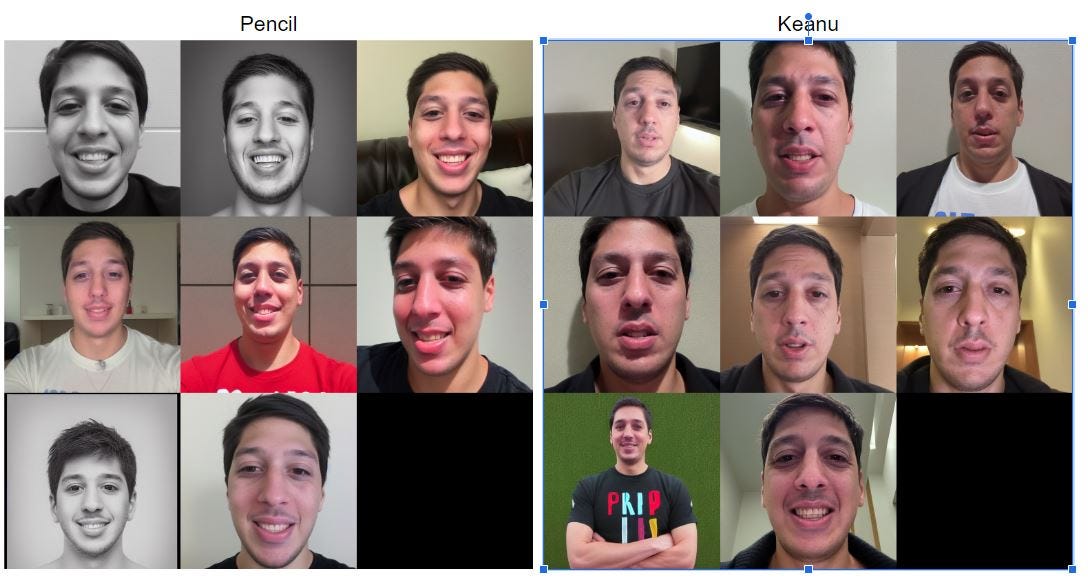
Model 8: 3000 Steps @ 6.00E-06
Pencil: No pencil sketches; faces look like trained ones but with some distortion
Keanu: Realistic-looking trained image bodies but no Keanu, with some artifacts

Model 9: 5000 Steps @ 6.00E-06
Pencil: Some images are all dark, and some have trained images with realistic faces with issues
Keanu: Most images are nothing; a few resemble the realistic trained face

Model 10: 8000 Steps @ 6.00E-06
Pencil: Some random faces, not pencil, not realistic
Keanu: Weird portraits with a bit of similarity to the trained face

Model 11: 700 Steps @ 3.33E-06
Pencil: All pencil sketches, some with a bit of similarity to the trained face
Keanu: A bit of promise here but nowhere close to astria

Model 12: 1200 Steps @ 3.33E-06
Pencil: Close to good but similarities are not on point
Keanu: It already seems overtrained, mostly the trained face

Model 13: 3000 Steps @ 3.33E-06
Pencil: Too realistic trained faces with some artifacts
Keanu: Too realistic trained faces with some artifacts

Model 14: 5000 Steps @ 3.33E-06
Pencil: Lot of artifacts and blurry images
Keanu: Lot of artifacts and blurry images

Model 15: 8000 Steps @ 3.33E-06
Pencil: just gray noise
Keanu: Just gray noise with a few shapes looking like training photos

Model 16: 700 Steps @ 2.00E-06
Pencil: A much better version of 11
Keanu: Some promise here but nowhere close to astria

Model 17: 1200 Steps @ 2.00E-06
Pencil: Almost good, but still no really good ones
Keanu: Bearly medium, too much of the trained face

Model 18: 3000 Steps @ 2.00E-06
Pencil: Close to medium, but similarities went down compared to 16 and 17
Keanu: Too much of a trained face, overtrained

Model 19: 5000 Steps @ 2.00E-06
Pencil: Overtrained, no more pencil sketches, and with some artifacts
Keanu: Lot of artifacts and realistic faces of training images

Model 20: 8000 Steps @ 2.00E-06
Pencil: Too realistic training faces with some artifacts
Keanu: Lot of artifacts and realistic faces of training images

Model 21: 700 Steps @ 1.00E-06
Pencil: A worse version of 11
Keanu: just Keanu

Model 22: 1200 Steps @ 1.00E-06
Pencil: A better version of 11
Keanu: Not much of a trained face there

Model 23: 3000 Steps @ 1.00E-06
Pencil: Decent but not as similar as the Astria version
Keanu: Now this seems undertrained, mostly Keanu and a bit of the trained face

Model 24: 5000 Steps @ 1.00E-06
Pencil: Astria level performance; hard to say which one is better
Keanu: Better than 25 but not as good as Astria

Model 25: 8000 Steps @ 1.00E-06
Pencil: Slightly overtrained; 24th is probably the best overall
Keanu: Seems overtrained. I see both the trained face and Keanu but not a single good one